这篇文章用作自己学习 k8s 的笔记,学习的资料为b站的视频
2021 年末倾力打造 Kubernetes 入门至精通 - 2022 年幸福的开胃菜_哔哩哔哩_bilibili
本文章为本人学习所用,如需转载请注明出处
1、基础概念
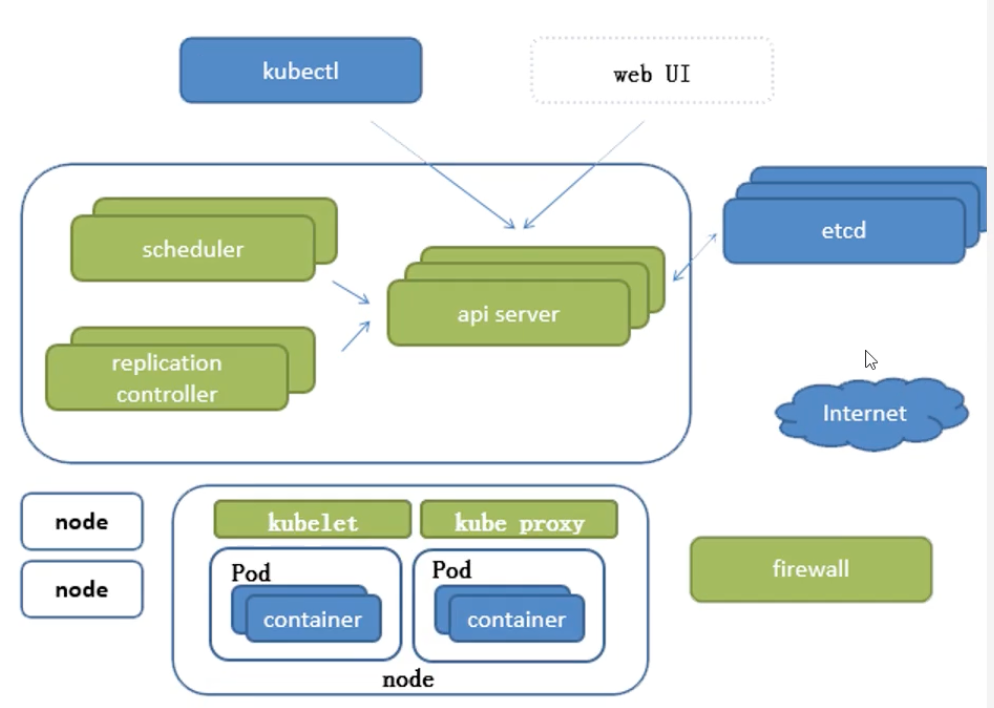
- 基础组件
- kubectl
- api server
- scheduler
- replication controller
- etcd
- kubelet
- kube proxy
- firewall
- 插件
- CoreDNS 负责为整个集群提供 DNS 服务
- Ingress Controller 为 k8s 中的服务提供外网入口
- Prometheus 为整个集群提供资源监控能力,时序数据库
- Dashboard 提供 B/S 的访问体系,允许用户通过 web 进行集群管理和设置,比较常用的如:rancher
- Federation 提供跨可用区的集群,提供不同数据中心的 K8S 集群的管理能力
2、Pod
在下达创建 pod 的时候,第一个被初始化的容器为pause,作用为初始化网络栈,挂载存储卷等。后续继续创建对应的 container,这些创建的 container 都会与初始容器pause 共享网络栈和存储等,类似 docker 中的--net和--volumes-from。这样在一个 Pod 中的 container 可以直接通过回环接口相互访问。
Pod种类
-
自主式 Pod
-
控制器管理的 Pod(推荐)
- ReplicationController & ReplicaSet & Deployment
- HPA(HorizontalPodAutoScale)
- StatefullSet
- DarmonSet
- Job & Cronjob
- 自定义控制器… 不做讨论
控制器种类
Replication Controller (RC)& ReplicaSet(RS) & Deployment
用来确保容器应用的副本数始终保持在用户定义的副本数,即如果有容器异常退出,会自动创建新的 Pod 来替代,而如果异常多出的容器也会自动回收。
在新版本的 K8S 中建议使用 RS 来取代 RC。
RS 的本质和 RC 没有本质区别,只是名字不一样,并且 RS 支持集合式的标签选择器(tag selector)。
虽然 RS 可以独立使用,但是一般建议使用 Deployment 来自动管理 RS,这样可以无需担心和其他机制不兼容的问题。比如 RS 不支持滚动更新(rolling-update)但 Deployment 支持。
滚动更新
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
# 更新前
Deployment「Pod模板:v1,副本数量:3」
└─ RS「副本数量:3」
├─ Pod:v1
├─ Pod:v1
└─ Pod:v1
# 更新Pod模板:v2
# 更新中:
Deployment「Pod模板:v1,副本数量:3」
├─ RS「副本数量:2」
│ ├── Pod:v1
│ └── Pod:v1
└─ RS「副本数量:1」
└─ Pod:v2
# 更新完毕:
Deployment「Pod模板:v1,副本数量:3」
├─ RS「副本数量:0」
└─ RS「副本数量:3」
├─ Pod:v2
├─ Pod:v2
└─ Pod:v2
|
滚动更新会创建一个新的 RS 控制器,以此来创建新版本的 Pod,此时把老版本的 RS 控制器的期望数量一个个调整至0,这样就完成了滚动更新。
HPA(HorizontalPodAutoScale)自动扩缩容
可以根据 Pod 的资源使用情况,调整副本数量,依赖于 RC、RS、Deployment 之上
StatefulSet
服务分类
- 有状态的服务
- 无状态服务
- 中心化服务
- 去中心化服务
为了解决有状态服务的问题而设计出来,可用来有序扩容缩,其应用场景包括:
- 稳定的持久化存储,即 Pod 重新调度后还是能访问到相同的持久化数据,基于 PVC 实现
- 稳定的网络标志,即 Pod 重新调度后,其 PodName 和 HostName 不变,基于 Headless Service(即没有 Cluster IP 的 Service)实现
- 有序部署,有序扩展,即 Pod 是有顺序的,在部署或者扩展的时候要依据定义的顺序依次进行(即从 0 到 N-1,在下一个 Pod 运行之前,所有之前的 Pod 必须都是 Running 和 Ready 状态),基于 init containers 来实现
- 有序收缩,有序删除(即 N-1到 0)
DaemonSet
确保全部(或者一些)Node 上运行一个 Pod 的副本。当有 Node 加入集群时,也会为他们新增一个 Pod。当有 Node 从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除所有由它创建的 Pod
经典用法:
- 运行集群存储 daemon,例如在每个 Node 上运行 glusterd,ceph
- 在每个 Node 上运行日志手机 deamon,例如 fluentd,logstash
- 在每个 Node 上运行监控 deamon,例如 Prometheus Node Exporter
Job & cronJob
Job 负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个 Pod 成功结束
Cron Job 管理基于时间的 Job,即:
网络模型
K8S 的网络模型假定了所有 Pod 都在一个可以直接连通的扁平的网络空间中,这在 GCE(Google Compute Engine)里面是现成的网络模型,K8S 假定这个网络已经存在。而在私有云里搭建 K8S 集群,就不能假定这个网络已经存在了。我们需要自己实现这个网络假设,将不同节点上的 Docker 容器之间的互相访问先打通,然后运行 K8S。
Flannel
Flannel 是 CoreOS 团队针对 Kubernetes 设计的一个网络规划服务,简单来说,它的功能是让集群中的不同节点主机创建的 Docker 容器都具有全集群唯一的虚拟 IP 地址。而且它还能在这些 IP 地址之间建立一个覆盖网络(Overlay Network),通过这个覆盖网络,将数据包原封不动地传输到目标容器内。基于 etcd 实现。
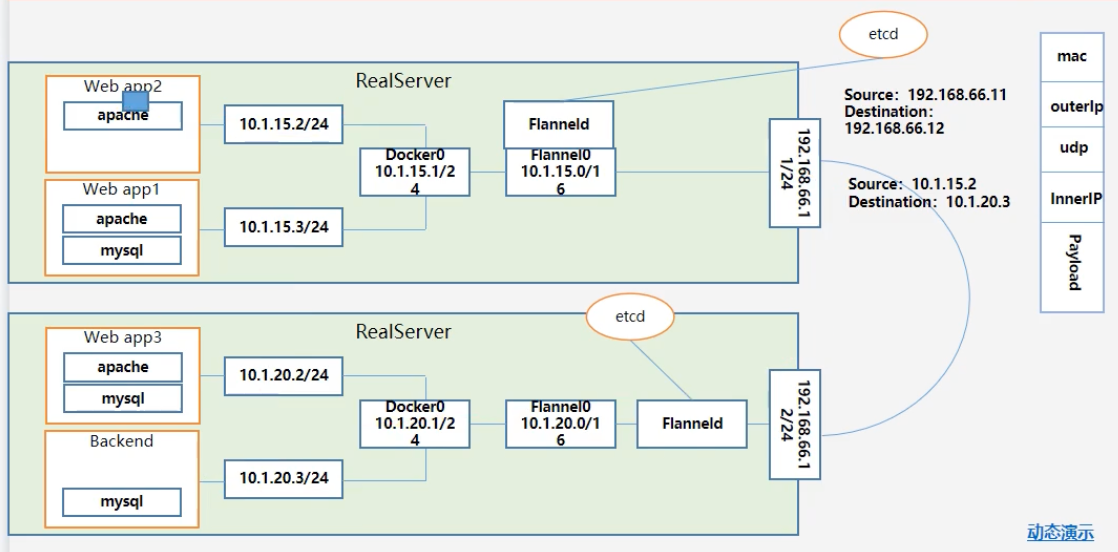
实现步骤:
- Flanneld 向 etcd 申请当前 Pod 的网段,修改当前 Docker0 的IP
- 会带上当前机器的物理网卡地址,这样就在 etcd 里标识了虚拟网段与真实IP之间的关系
- 当一个 Pod 发送网络数据的时候,通过对方的虚拟IP就可以找到真实IP了
- 请求流转(根据图观察)
- app2 发送一个数据包给
10.1.20.3,发现无法直接访问,数据包传递给网关
- 此时数据包被 Flanneld 所捕获(Flannel0 监听的为 10.1.15.0,注意这个0)传递给对应的另外一个 Flanneld(从etcd获取)
- 此时 Flanneld 会对数据包进行二次封装,类似一个快递里是另外一个快递
- 接收到数据包后进行拆包,在对应的 Docker0 中广播,这样也就能收到了
- 回应同理
网络通讯模式
- 同 Pod 间不同容器间的网络通讯:本地回环
- 不同 Pod 间的通讯
- 同物理机:Docker0 网桥实现报文转发
- 不同物理机:flannel UDP 数据包二次封装
- svc 网络与 Pod 间的通讯
- 隔离:namespace network
3、K8S安装
前置准备
-
安装配置
- 推荐安装在单网卡机器
- CPU >= 2,内存 3G 以上,磁盘 100G
- 关闭 SWAP
- 分区
- seliunx,firewall stop,iptable none
-
K8S安装3个节点,可以配置一个软路由,双网卡
-
安装工具包(可选)
1
|
sudo apt-get install -y conntrack ntpdate ntp ipvsadm ipset iptables curl sysstat wget net-tools git
|
-
同步时区
1
2
|
sudo apt install ntpdate
sudo ntpdate ntp.aliyun.com
|
-
关闭swap
1
2
|
sudo swapoff -a # 临时关闭
sed -ri 's/.swap./#&/' /etc/fstab # 永久关闭
|
-
允许 iptables 桥接流量
1
2
3
4
5
6
7
8
9
10
11
12
13
|
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
br_netfilter
EOF
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
# 设置网卡允许转发 ipv4 流量
sudo sysctl -w net.ipv4.ip_forward=1
sudo sysctl --system
|
安装 Kubernetes
- 源码包编译安装(难度过高)
- 容器化安装
- kubeadm 官方
- 证书有效期 1 年(需要修改源码,设置生成证书有效时间)
- rancher
- sealos
1、安装容器组件
2、安装 Kubeadm (主从配置)
Kubeadm 启动流程
Master
Systemd > kubelet > 容器组件 > Kubernetes
容器组件在 k8s v1.24.0 版本已弃用 Docker shim
使用了新组件 CRI DOCKERD
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# 添加阿里云镜像源
sudo apt update && sudo apt install -y apt-transport-https
sudo curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add -
# 添加阿里云或者官方 api 源
# 阿里云
echo "deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list
# 官方
sudo curl -o /usr/share/keyrings/kubernetes-archive-keyring.gpg https://packages.cloud.google.com/apt/doc/apt-key.gpg
echo "deb [signed-by=/usr/share/keyrings/kubernetes-archive-keyring.gpg] https://apt.kubernetes.io/ kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list
# 安装软件
sudo apt update && sudo apt install -y kubelet kubeadm kubectl
# 开机自启
systemctl enable kubelet.service
# 注意,此时可能 kublet 没正常运行,不用管继续往下走
|
3、初始化主节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
# 打印 kubeadm 默认配置
sudo kubeadm config print init-defaults > kubeadm-config.yaml
# 修改:`localAPIEndpoint.advertiseAddress`的值为当前主节点的 ip 地址
...
localAPIEndpoint:
advertiseAddress: 1.2.3.4 # 这里
bindPort: 6443
...
# 修改:`nodeRegistration.name` 的值为当前主节点名称
···
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
imagePullPolicy: IfNotPresent
name: k8s-master01 # 这里
taints: null
···
# 添加 Pod 网段,Flannel 需要工作在指定的网段
...
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
podSubnet: 10.244.0.0/16 # 新增该行
···
# 设置负载均衡方式为 ipvs(可选),下列配置添加到末尾,注意 --- 也需要添加
···
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
featureGates:
SupportIPVSProxyMode: true
mode: ipvs
···
# k8s.gcr.io 国内无法直接访问,所以替换为阿里云镜像地址
sed -i 's/k8s.gcr.io/registry.cn-hangzhou.aliyuncs.com\/google_containers/g' kubeadm-config.yaml
# 配置文件准备完毕,开始初始化
sudo kubeadm init --config=kubeadm-config.yaml --ignore-preflight-errors=all --v=5 | tee kubeadm-init.log
# 初始化成功根据页面提示
# 非 root 用户
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# root 用户
export KUBECONFIG=/etc/kubernetes/admin.conf
# 查看集群信息
kubectl cluster-info
|
4、工作节点加入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
# 在初始化主节点成功后,打印出的日志内的最后一段,告诉了我们应该如何加入一个主节点
# 也可以 cat kubeadm-init.log 查看
# 加入前查看当前主机名称 hostnamectl,可以修改为自己便于识别的名称
sudo hostnamectl set-hostname k8s-node01 --static
# 加入节点
sudo kubeadm join 192.168.31.100:6443 --token xxx.xxx \
--discovery-token-ca-cert-hash sha256:xxx
# 如果提示 unable to fetch the kubeadm-config ConfigMap: faild to get config map: Unauthorized
# 这个代表 token 过期,重新生成即可
sudo kubeadm token create --ttl 0 --print-join-command
# 如果提示
# [kubelet-check] Initial timeout of 40s passed.
# error execution phase kubelet-start: error uploading crisocket: timed out waiting for the condition
# To see the stack trace of this error execute with --v=5 or higher
sudo kubeadm reset -f
|
5、工作节点退出
1
2
3
4
5
6
7
8
9
10
|
# 1、将节点设置为维护模式
kubectl drain k8s-node01 --delete-local-data --force --ignore-daemonsets node/k8s-node01
# 2、删除节点
kubectl delete node k8s-node01
# 登陆上节点机器
# 3、停止 kubelet
systemctl stop kubelet
# 4、k8s 重置
sudo kubeadm reset -f
|
6、创建网络「flannel」
1
2
3
4
5
6
7
8
9
10
11
|
# 拷贝配置文件
sudo mkdir -p /usr/local/kubernetes/cni/flannel/
cd /usr/local/kubernetes/cni/flannel/
wget https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml
# 应用配置
kubectl apply -f kube-flannel.yml
# 等待2~3分钟,查看是否成功
kubectl get nodes
# 可以看到所有节点都显示 ready
|
7、集群测试
7.1、创建pod
1
2
3
4
|
# 创建一个 deployment 任务 指定镜像
kubectl create deployment nginx --image=nginx
# 获取 pod 列表
kubectl get po -o wide
|

7.2、创建 svc 网络
1
2
3
4
|
# 创建一个 svc 网络
kubectl create svc clusterip nginx --tcp=80:80
# 查看当前 svc 网络
kubectl get svc
|

4、资源清单
在 k8s 中所有的内容都是资源,资源实例化之后,叫做对象
资源:
- 命名空间级别
- 工作负载型资源:Pod、ReplicaSet、Deployment 等
- 服务发现及负载均衡型资源:Service、Ingress 等
- 配置与存储型资源:Volume、CSI 等
- 特殊类型的存储卷:ConfigMap、Secre 等
- 集群级资源
- Namespace、Node、ClusterRole、ClusterRoleBinding
- 元数据类型资源
- HPA、PodTemplate、LimitRange
在 k8s 中,一般使用 yaml 格式的文件来创建符合我们预期期望的对象,这样的 yaml 文件我们一般称为资源清单
格式
1
2
3
4
5
6
7
8
9
10
|
apiVersion: group/apiversion # 如果没有给定 group 名称,那么默认为 core,可以使用 kubectl apt-versions 获取当前 k8s 版本上所有的 apiVersion 版本信息(每个版本可能不同)
kind: # 资源类别
metadate: # 资源元数据
name
namespace
lables
annotations # 主要目的是方便用户阅读查找
spec: # 期望的状态 (disired state)
status: # 当前状态,本字段由 kubernetes 自身维护,用户不能定义
|
常用命令
必须记住的命令 kubectl explain xxx.xxx
必须记住的命令 kubectl explain xxx.xxx
必须记住的命令 kubectl explain xxx.xxx
1
2
3
4
5
6
7
8
9
10
11
12
|
# 查询
# -n 指定命名空间,默认为 default
kuebctl get pod -o wide -l [key/key=values] # 获取 pod 列表
kubectl get pod podName -o json/yaml # 获取 pod 详细信息
kubectl log podName # 获取 pod 日志
kubectl describe pod podName # 获取 pod 事件信息
# 操作
kubectl create -f filename # 创建资源
kubectl exec -it podName -c containerName -- [script] # 在某个容器内执行脚本
kubectl delete [res] [--all | name] # 删除资源
kubectl scale --replicas=[num] [controllerKind]/[resName] # 修改某个控制器的副本数量
|
获取 apiversion 版本信息
1
2
3
4
5
6
7
|
kubectl api-versions
# output:
admissionregistration.k8s.io/v1
apiextensions.k8s.io/v1
apiregistration.k8s.io/v1
apps/v1
...
|
字段配置格式
1
2
3
4
5
6
7
8
|
apiVersion <string> # 表示字符串类型
metadata <object> # 表示需要嵌套多层字段
labels <map[string]string> # 表示由 k:v 组成的映射
finalizers <[]string> # 表示字符串列表
ownerReferences <[]object> # 表示对象列表
hostPID <boolean> # true | flase
priority <integer> # 整型
name <string> -required- # 如果类型后面接 required,表示为必填字段
|
通过定义清单文件创建 Pod
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
apiVersion: v1
kind: Pod
metadate:
name: pod-demo
namespace: default
lables:
app: myPod
spec:
containers:
- name: myPod-1
image: nginx
- name: myPod-2
image: busybos:1.34.1
command:
- "/bin/sh"
- "-c"
- "sleep 3600"
|
1
2
|
# 使用 -o 选项加 yaml,可以将资源的配置以 yaml 的格式输出,也可以使用 json
kubectl get pod xxx.xxx.xxx -o yaml
|
5、Pod 生命周期
执行流程
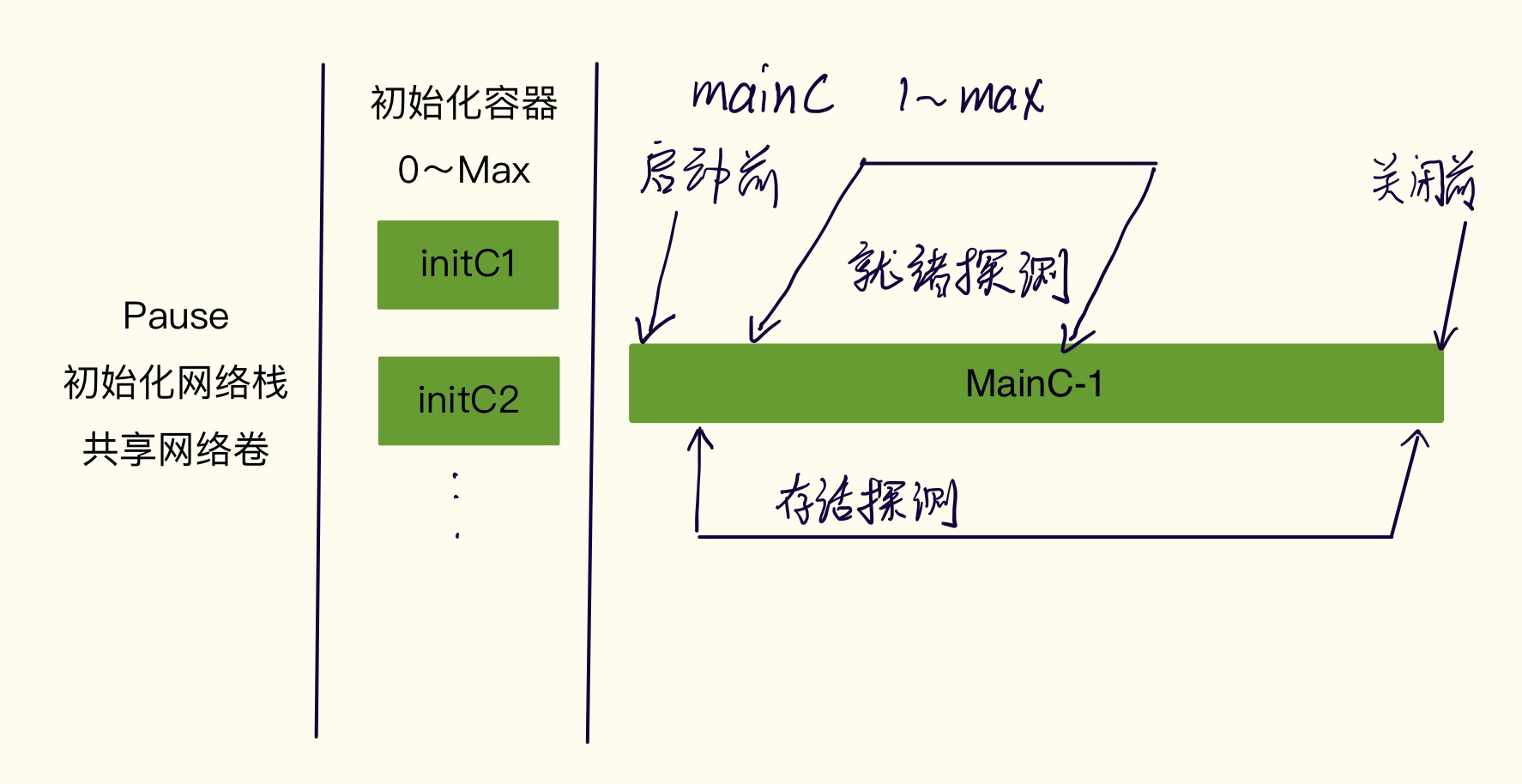
- Pause:在一个 Pod 启动前,会先启动一个 Pause 容器。它会初始化相应的网络栈,同时把自身的网络卷共享给 Pod 内的容器
- 初始化容器「initC」,可以有0到无限个
- 它是批处理类型的任务
- 它的运行是有序的,第一个不运行成功,第二个不会运行
- 如果执行失败,会直接重载整个 Pod,直到 Init 容器成功为止。然而,如果 Pod 对应的 restartPolicy 为 Never 则不会重启
- 主容器「mainC」,至少存在一个
- 多个 mainC 并行启动
- 多个 mainC 共享同一个网络卷,绑定的端口不能重复
- hook
- 启动前「和主进程同时运行,不一定在主进程运行前执行完成」
- 关闭前「可以保证在关闭前执行完成」
- 探针「tcp|http|script」
- 可以进行就绪、存活探测探针:判断是否可以进行后续探针,新版本才存在
- 就绪探针:判断一个 mainC 是否已经准备好提供服务,可以定义探测间隔
- 存活探针:判断一个 mainC 是否存活,如无响应则重启容器
init 容器
因为 Init 容器具有与应用容器分离的单独镜像,所以它们的启动相关代码具有如下优势:
- 它们可以包含并运行实用工具,但是出于安全考虑,不建议在应用容器镜像中包含这些工具
- 应用程序镜像可以分离出创建和部署的角色,而没有必要联合它们构建一个单独的镜像
- Init 容器使用 Linux Namespace,所以相对于应用容器来说具有不同的文件系统视图。因此,他们能够具有访问 Secret 的权限,而应用程序则不能
- 他们必须在应用容器启动之前运行完成,而应用容器是并行运行的,所以 Init 容器能够提供一种简单的阻塞或延迟应用容器启动的方法,直到满足啦一组先决条件
- Init 容器具有应用容器的所有字段。除了 readinessProbe,因为 Init 容器无法定义不同于完成和就绪之外的其他状态,这会在验证过程中强制执行
- 在 Pod 中的每个 app 和 init 容器的名称必须唯一;与其他任何容器共享同一个名称,会在验证时抛出错误
简单实操
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
# testpod.yaml
apiVersion: v1
kind: Pod
metadata:
name: my-nginx-pod
labels:
app: my-nginx
spec:
containers:
- name: my-nginx
image: nginx
initContainers:
- name: init-my-service
image: busybox
command: ['sh', '-c', 'until nslookup my-service; do echo waiting for my-service; sleep 2; done;']
- name: init-my-db
image: busybox
command: ['sh', '-c', 'until nslookup my-db; do echo waiting for my-db; sleep 2; done;']
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
# init-testpod.yaml
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376
---
apiVersion: v1
kind: Service
metadata:
name: my-db
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9377
|
先创建 init 模板
1
|
kubectl create -f init-pod.yaml
|
查看 Pod 状态

查看初始化容器日志
1
|
kubectl logs my-nginx-pod -c init-my-service
|
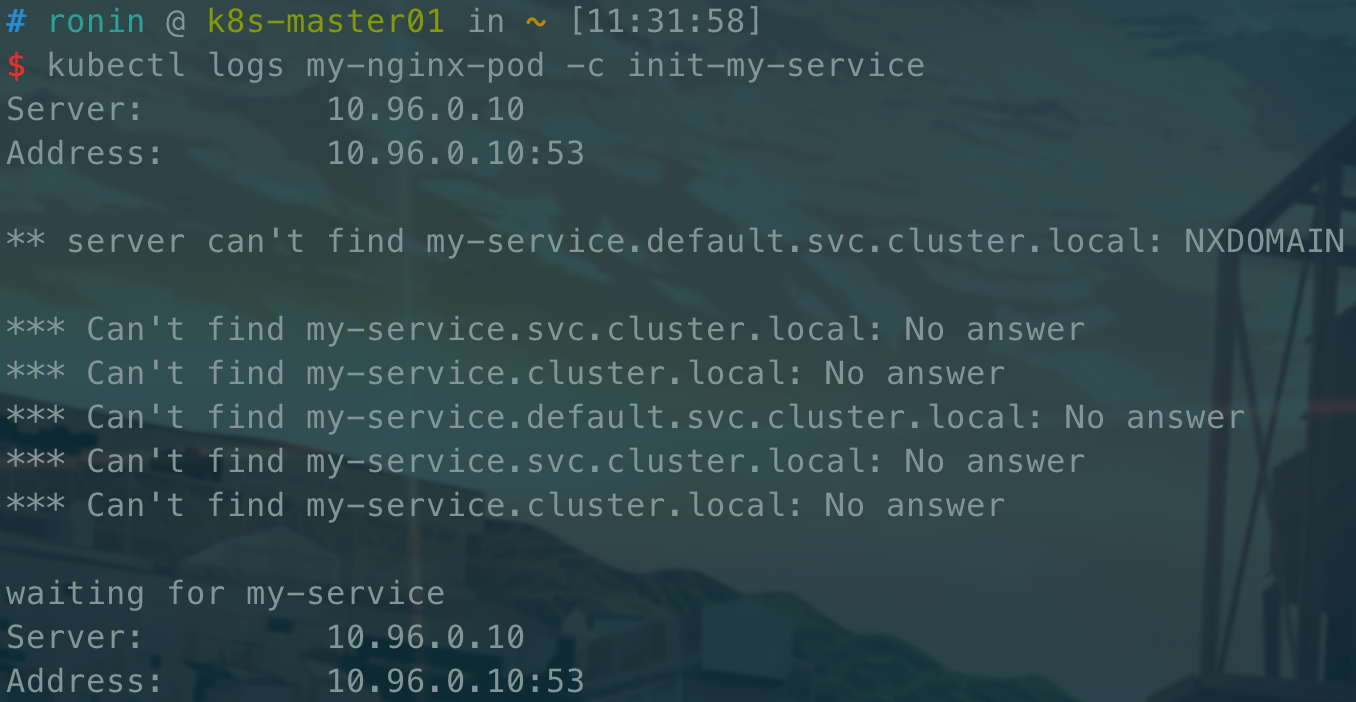
发现一直在解析域名,这时我们创建响应的 service
1
|
kubectl create -f init-test-pod.yaml
|

然后我们再去查看容器的状态,可能需要等待一定的时间

探针
探针是由 kubelet 对容器执行的定期诊断,要执行诊断,kubelet 调用容器实现的 Handler。有三种类型的处理程序:
- ExecAction:在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功
- TCPSocketAction:对指定端口上的容器 IP 地址进行 TCP 检查。如果端口打开,则诊断被任务时成功的
- HTTPGetAction:对指定的端口和路径上的容器 IP 地址执行 HTTP Get 请求。如果响应的状态码大于等于 200 且小于 400,则诊断被认为是成功的
每次探测都将获得以下三种结果:
- 成功:容器通过诊断
- 失败:容器未通过诊断
- 未知:诊断失败,但不会采取任何行动
readinessProbe「就绪探针」
指示容器是否准备好服务请求。如果就绪探测失败,端点控制器将从与 Pod 匹配的所有 Service 的端点中删除该 Pod 的 IP 地址。初始延迟前的就绪状态默认为 Failure。如果容器不提供就绪探针,则默认状态为 SUCCESS
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# readinessProbe-httpget
apiVersion: v1
kind: Pod
metadata:
name: reaadiness-httpget-pod
namespace: default
labels:
app: myapp
spec:
containers:
- name: readiness-httpget-container
image: nginx
imagePullPolice: IfNotPresent
readinessProbe: # 配置就绪探针
httpGet: # 探针类型,请求端口和 path
port: 80
path: readiness.html
initialDelaySeconds: 1 # 开始探测延迟
periodSeconds: 3 # 探测间隔
|
创建该 Pod 后,会发现 Pod 处于运行状态,但是 READY 却是 0/1。这时我们查看容器日志,发现探针返回为 404,此时表示探针正常生效。
我们进入容器,在 nginx 的根目录下创建readiness.html文件,退出后发现容器已处于就绪状态。
livenessProbe「存活探针」
指示容器是否正在运行。如果存活探测失败,则 kubelet 会杀死容器,并且容器将根据重启策略来判断是否重新拉起。如果容器不提供存活探针,则默认状态为 SUCCESS
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# livenessProbe-exec
apiVersion: v1
kind: Pod
metadata:
name: liveness-exec-pod
namespace: default
spec:
containers:
- name: liveness-exec-container
image: busybox
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c", "touch /tmp/live; sleep 60; rm -rf /tmp/live; sleep 3600"] # 运行脚本
livenessProbe:
exec: # exec 类型探针
command: ["test", "-e", "/tmp/live"] # 执行脚本
initialDelaySeconds: 1 # 开始探测延迟
periodSeconds: 3 # 探测间隔
|
创建该 Pod 后,在前 60 秒内正常运行,之后发现 Pod 被杀死并重新创建。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# livenessProbe-httpget
apiVersion: v1
kind: Pod
metadata:
name: liveness-httpget-pod
namespace: default
spec:
containers:
- name: liveness-httpget-container
image: nginx
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
livenessProbe:
httpGet: # 探针类型,请求端口和 path
port: 80
path: index.html
initialDelaySeconds: 3 # 开始探测延迟
periodSeconds: 3 # 探测间隔
timeoutSeconds: 3 # 超时时间
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# livenessProbe-tcp
apiVersion: v1
kind: Pod
metadata:
name: liveness-tcp-pod
namespace: default
spec:
containers:
- name: liveness-tcp-container
image: nginx
imagePullPolicy: IfNotPresent
ports:
- name: tcp
containerPort: 80
livenessProbe:
tcpSocket: # 探针类型,请求端口
port: 80
initialDelaySeconds: 5 # 开始探测延迟
timeoutSeconds: 1 # 超时时间
|
启动、退出动作「hook」
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle: # 生命周期
postStart: # 启动前
exec:
command: ["/bin/sh", "-c", "echo postStart > /usr/share/message"]
preStart: # 关闭前
exec:
command: ["/bin/sh", "-c", "echo preStart > /usr/share/message"]
|
在进入容器后,就可以看到/usr/share/message存在,并且内容是我们自定义的postStart。我们进去容器死循环打印文件
1
|
while true; do cat /usr/share/message; done
|
在外部关闭容器后,发现打印变成了preStart
6、控制器详解
RC 控制器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# file: rc.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: frontend
spec:
replicas: 3 # 副本数量
selector: # 标签选择器,寻找 app=nginx 的 Pod
app: nginx
template: # 创建 Pod 模板
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
|
在创建上述文件后,我们执行
1
|
kubectl create -f rc.yaml
|
然后我们查看对应 Pod:
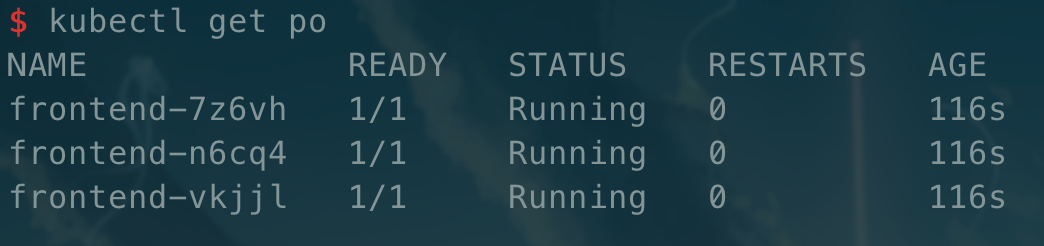
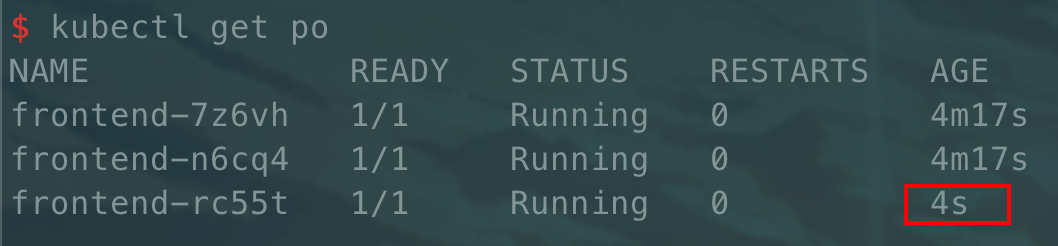
这也就是 RC 控制器的功能,我们可以尝试删除其中一个 Pod 会发现又被重新创建
RS 控制器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
apiVersion: v1
kind: ReplicaSet
metadata:
name: frontend
spec:
replicas: 3 # 副本数量
selector: # 标签选择器,寻找 app=nginx 的 Pod
matchLabels:
app: nginx1
# matchExpressions: 可选
template: # 创建 Pod 模板
metadata:
labels:
app: nginx1
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
|
RS 控制器相比 RC 控制器,只是多了一种标签选择器,我们可以通过下面的命令查看对应的文档:
1
|
kubectl explain rs.spec.selector
|
可以看到除了和 RC 控制器功能一致的matchLabels,还多了一种matchExpressions可选择。
matchExpressions目前能支持的操作包括:
- In:label 的值在某个列表中
- NotIn:label 的值不在某一个列表中
- Exists:某个 label 存在
- DoesNotExist:某个 label 不存在
示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
# selector exists demo
apiVersion: v1
kind: ReplicaSet
metadata:
name: rs-demo
spec:
selector:
matchExpressions: # 这里
- key: app
operator: Exists # label 中 key 为 app 存在即可
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# selector In demo
apiVersion: v1
kind: ReplicaSet
metadata:
name: rs-demo
spec:
selector:
matchExpressions: # 这里
- key: app
operator: In # label 中 key 对应的 value 在枚举的 values 中即可
values:
- nginx
- nginx1
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
|
Deployment 控制器
命令的定义方式
- 命令式定义 kubectl create -f xxxxx
- 声明式定义 kubectl apply -f xxxxx
区别:声明式命令可以重复使用,系统会自动判断当前操作是修改还是创建
推荐直接使用 apply,在遇到命令式资源时会自动降级成命令式
Deployment 为 Pod 和 ReplicaSet 提供来一个声明式定义方法,用来代替之前的 ReplicationController 来方便管理应用。典型的应用场景包括:
- 定义 Deployment 来创建 Pod 和 ReplicaSet
- 滚动升级和回滚应用
- 扩容和缩容
- 暂停和继续 Deployment
1、部署一个简单的 Nginx 应用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
template:
metadate:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
|
1
2
|
kubectl apply -f https://kubernetes.io/docs/user-guide/nginx-deployment.yaml --record
# --record 可以记录当前命令到 deployment 到历史记录中
|
2、扩容
1
2
|
# 修改副本数量为 10,不会影响 deployment 已经创建的 rs
kubectl scale deployment nginx-deployment --replicas 10
|
如果集群支持 horizontal pod autoscaling 的话,还可以为 Deployment 设置自动扩展
1
|
kubectl autoscale deployment nginx-deployment --min=10 --max=15 --cpu-percent=80
|
3、更新镜像
1
|
kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1
|
4、回滚
1
|
kubectl rollout undo deployment/nginx-deployment
|
假如当前有4个版本 v1、v2、v3、v4,目前的版本为 v4,使用上述命令回滚之后回滚到 v3 版本,再次使用上述命令,此时回重新回滚到 v4 版本,因为当前的上一个版本为 v4,如果想指定版本可以使用下述命令:
1
2
3
4
5
6
7
8
9
|
# 查看历史版本记录,如果使用了 --replicas 会显示当时的命令
kubectl rollout history deployment/nginx-deployment
# 回滚到指定版本
kubectl rollout undo deployment/nginx-deployment --to-revision=2
# 暂停 deployment 的更新
kubectl rollout pause deployment/nginx-deployment
# 可以使用 kubectl rollout status 查看回滚是否完成,同时命令返回 code 为 0,可以使用脚本来判断
kubectl rollout status depoyment/nginx-deployment
|
限制版本数量
可以设置.spec.revisionHistoryLimit来设置保留的版本数量,这个数量也就是 deployment 管理的历史 rs 数量
多个 rollout 并行
假设当前有 10 个 Pod 正在从 v1 版本升级至 v2 版本,此时 v1 : 5、v2 : 5。
这时我们再升级至 v3 版本,此时升级的 5 个 v2 版本的 Pod 会直接被杀死,然后直接创建 v3 版本的 Pod。
常用回滚策略
一般在企业中不会使用 revision 这种回滚方式,而是会复制最近版本的配置文件,修改名称后直接进行 apply 操作,比如nginx-deployment-2022-06-06 12:00:00.yaml。这样的话出现问题可以直接 apply 至上一个配置文件即可。
5、更新策略
Deployment 可以保证在升级时只有一定数量的 Pod 是 down 的。默认它会确保至少有比期望的副本数量少一个为 up 状态,也就是最多一个不可用
同时也可以确保只创建出超过期望一定数量的 Pod,默认会比期望的副本数量多一个是 up 状态
未来的 kuberentes 版本中,将从 1-1 变成 25%-25%
当然,也支持自定义更新策略
kubectl explain deploy.spec.strategy.type
- Recreate:重新创建
- rollingUpdate:滚动更新(推荐)
- maxSurge:指定超出副本数有几个,两种方式:1、指定数量 2、百分比
- maxUnavailable:指定副本数量最多有几个不可用
1
2
3
4
5
6
7
|
# 查询当前更新策略
kubectl describe deployments {控制器名称} # 找到 RollingUpdateStrategy
# 修改当前更新策略
kubectl edit deployment {控制器名称} # 找到 rollingUpdate
# 或者使用 patch 打补丁
kubectl patch deployment nginx-deployment -p '{"spec": {"strategy": {"rollingUpdate": {"maxSurge":1, "maxUnavailable": 0}}}}'
|
6、金丝雀部署
1
2
3
4
5
6
7
8
9
10
|
# 需要设置当前更新策略为 maxSurge:1 maxUnavailable:0
kubectl patch deployment nginx-deployment -p '{"spec": {"strategy": {"rollingUpdate": {"maxSurge":1, "maxUnavailable": 0}}}}'
# 开始更新后直接暂停,此时只会新建一个新版本的 Pod,旧版本的 Pod 不会进行删除
# 此时 svc 网络会将流量负载均衡至当前全部 Pod,就可以测试新版本了
kubectl set image deployment nginx-deployment nginx=nginx:1.9.1 \
&& kubectl rollout pause deployment nginx-deployment
# 等待测试结束后,继续更新
kubectl rollout resume deployment nginx-deployment
|
DaemonSet
DaemonSet 确保全部(或者一些)Node 上运行一个 Pod 的副本。当有 Node 假如集群时,也会为他们新增一个 Pod。当有 Node 从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod
使用 DaemonSet 的一些典型用法:
- 运行集群存储 daemon,例如在每个 Node 上运行
glusterd、ceph
- 在每个 Node 上运行日志收集 daemon,例如
fluentd、logstash
- 在每个 Node 上运行监控 darmon,例如
Promentheus Node Exproter、collectd、Datadog代理、New Relic 代理或者Ganglia gmond
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: daemonset-example
labels:
app: daemonset
spec:
selector:
matchLabels:
name: daemonset-example
template:
metadata:
labels:
name: daemonset-example
spec:
containers:
- name: daemonset-example
image: nginx
|
Job
Job 负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个 Pod 成功结束
特殊说明
.spec.template格式同 Pod- RestartPolicy 仅支持 Never 或者 OnFailure
- 当个 Pod 时,默认 Pod 运行成功后 Job 即结束
.spec.completions标志 Job 结束需要成功运行的 Pod 个数,默认为 1.spec.parallelism标志并行运行的 Pod 个数,默认为 1spec.activeDeadlineSecods标志失败 Pod 的重试最大时间,超过这个时间不会继续重试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
apiVersion: batch/v1
kind: Job
metadata:
name: job
spec:
template:
metadata:
name: job
spec:
containers:
- name: job
image: busybox
command: ['echo', 'this is a job container']
restartPolicy: Never
|
CronJob
CronJob 基于时间管理的 Job,即:
- 在给定的时间点只运行一次
- 周期性的在给定时间点运行
使用条件:当前使用 k8s 集群,版本 >= 1.8
典型用法:
- 在给定的时间点调度 Job 运行
- 创建周期性运行的 Job,例如:数据库备份、发送邮件
Spec
-
.spec.schedule:调度,必须字段,指定任务运行周期,格式同 Cron
-
.spec.jobTemplate:Job 模板,必须字段,指定需要运行的任务,格式同 Job
-
.spec.startingDeadlineSeconds:启动 Job 的时间(秒),选填,超出该时间未启动认定为失败,默认没有期限
-
.spce.concurrencyPolicy:并发策略,选填,指定 Job 的并发执行,只允许以下策略:
- Allow (默认):允许并发运行
- Forbid: 禁止并发运行,如果前一个还没有完成,则跳过
- Replace:取消当前正在运行的 Job,用一个新的替换
以上策略只能应用于同一个 CronJob 创建的 Job,如果存在多个 CronJob,它们之间总是互不干涉的
7、Service
Kubernetes Service 定义了这样一种抽象:
一个 Pod 的逻辑分组,一种可以访问它们的策略,通常称为 微服务
这一组 Pod 能够被 Service 访问到,通常是通过 Label Selector
核心迭代
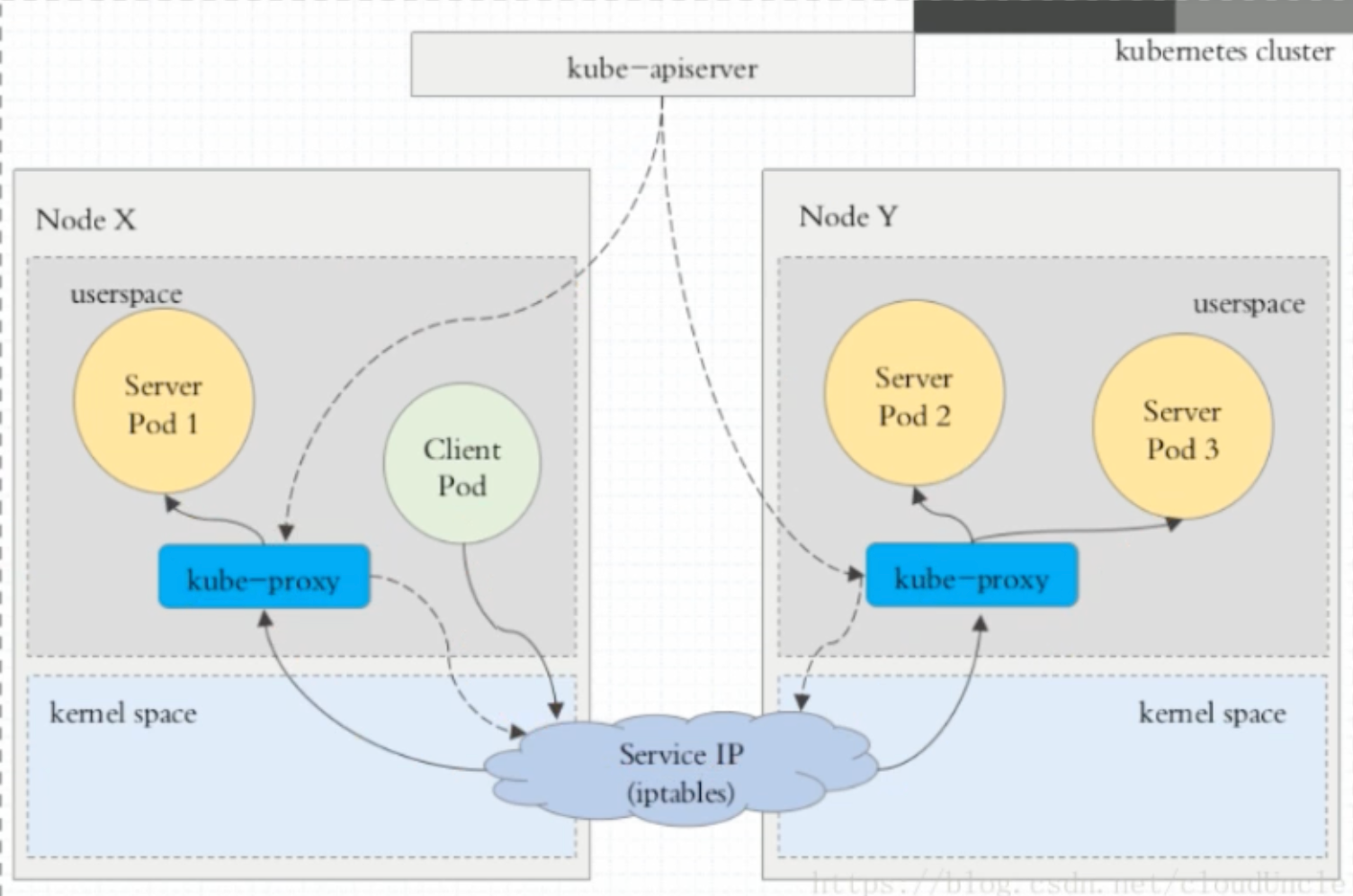
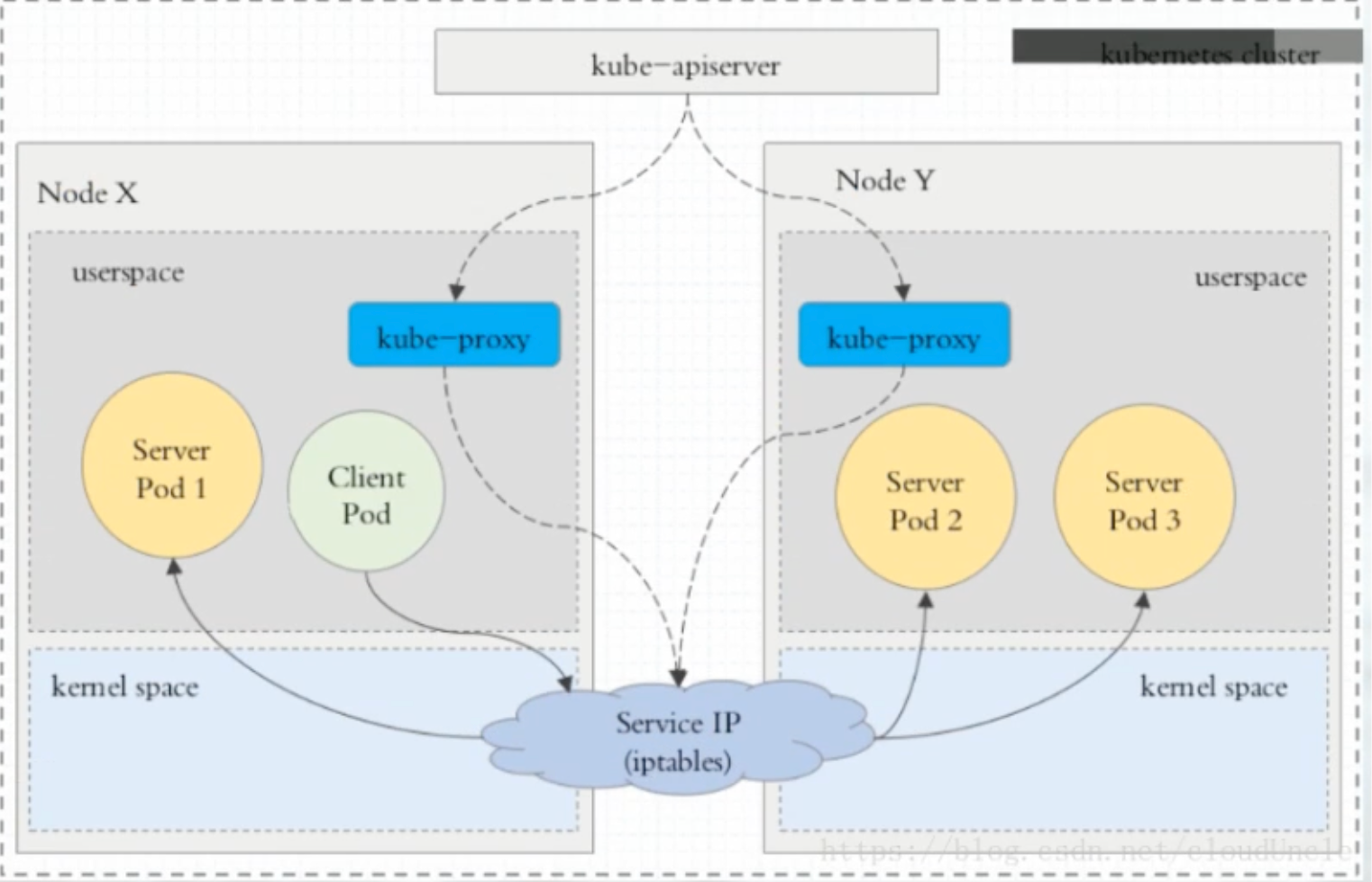
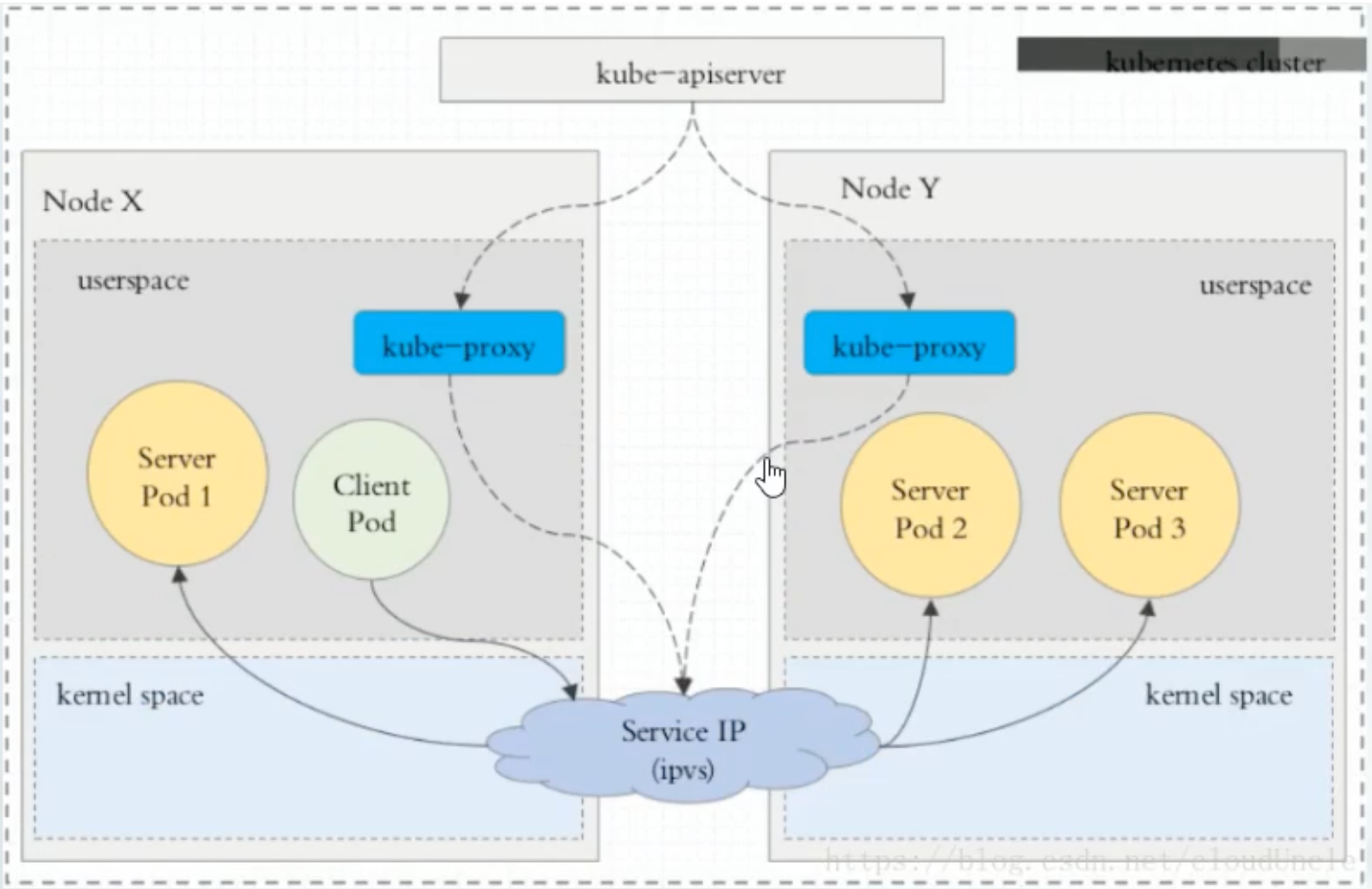
在 Kubernetes 集群中,每一个 Node 运行一个 kube-proxy进程。kube-proxy 负责为 Service实现一种 VIP(虚拟IP)的形式,而不是ExternalName的形式。在 Kubernetes v1.0 版本,代理完全在 userspace。在 Kubernetes v1.1 版本,增加了 iptables 代理,但并不是默认的运行模式。从 Kubernetes v1.2 起,默认就是 iptables 代理。在 Kubernetes v1.8.0-beta.0 中,添加了 ipvs 代理。在 Kubernetes v1.14 版本开始默认使用 ipvs 代理。
在 Kubernetes v1.0 版本,Service 是 4层(TCP/UDP over IP)概念。在 Kubernetes v1.1 版本,新增了 Ingress API(beta 版),用来表示 7层(HTTP)服务。
1、userspace 代理模式
2、iptables 代理模式
3、ipvs 代理模式
注意:ipvs 模式假定运行 kube-proxy 之前在节点上都已经安装了 IPVS 内核模块。当 kube-proxy以 ipvs 代理模式启动时,kube-proxy 将验证节点是否安装 IPVS 模块,如果未安装,则回退到 iptables 代理模式
限制
Service 能够提供负载均衡的能力,但是在使用上有以下限制:
- 只提供 4 层负载均衡能力,没有 7 层的功能,但有时我们需要更多的匹配规则来转发请求,这点 4 层负载均衡是不支持的
类型
- ClusterIP:默认类型,自动分配一个仅 Cluster 内部可以访问的虚拟 IP
- NodePort:在 Cluster Ip 基础上为 Service 在每台机器上绑定一个端口,这样就可以通过 : 来访问服务
- LoadBalancer:在 NodePort 的基础上,结束 cloud provider 创建一个外部负载均衡器,并将请求转发到 :
- ExternalName:把集群外部的服务引入到集群内部来,在集群内部直接使用。没有任何类型代理被创建,这自由 Kubernetes 1.7 或更高版本的 kube-dns 才支持
1、ClusterIP
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
apiVersion: v1
kind: Service
metadata:
name: myapp
namespace: default
spec:
type: ClusterIP
selector:
app: myapp
relese: stable
ports:
- name: http
port: 80
targetPort: 80
|
Headless Service
有时不需要或不想要负载均衡,以及单独的 Service IP。 遇到这种情况,可以通过指定 Cluster IP(spec.clusterIP)的值为 "None" 来创建 Headless Service。
你可以使用一个无头 Service 与其他服务发现机制进行接口,而不必与 Kubernetes 的实现捆绑在一起。
对于无头 Services 并不会分配 Cluster IP,kube-proxy 不会处理它们, 而且平台也不会为它们进行负载均衡和路由。 DNS 如何实现自动配置,依赖于 Service 是否定义了选择算符。
1
2
3
4
5
6
7
8
9
10
11
12
|
apiVersion: v1
kind: Service
metadata:
name: myapp-headless
namespace: default
spec:
selector:
app: myapp
clusterIP: "None"
ports:
- port: 80
targetPort: 80
|
2、NodePort
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
apiVersion: v1
kind: Service
metadata:
name: myapp-nodeport
namespace: default
spec:
type: NodePort
selector:
app: myapp
relese: stable
ports:
- name: http
port: 80
targetPort: 80
nodePort: 30000 # 可指定
|
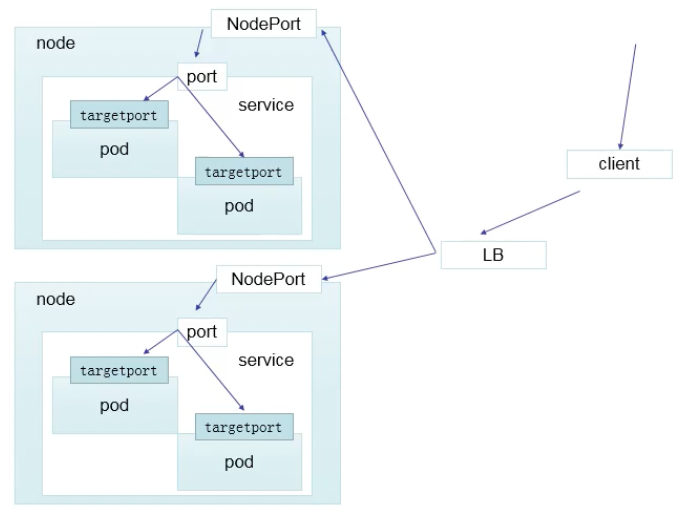
3、LoadBalancer
loadBalacer 和 nodePort 其实是同一种方式,区别在于 loadBalancer 比 nodePort 多了一步,就是可以调用 cloud provider 去创建 LB 来向节点导流
4、ExternalName
可以将服务映射到 ExternalName 字段的内容(例如:myapp.otherNS)。ExternalName Service 是 Service 的特例,它没有 selector,也没有定义任何的端口和 Endpoint。相反的、对于运行在集群外部的服务,它通过返回外部服务的别名这种方式来提供服务
1
2
3
4
5
6
7
8
|
kind: Service
apiVersion: v1
metadata:
name: my-service
namespace: default
spec:
type: ExternalName
externalName: myapp.otherNS
|
但查询主机my-service.default.svc.cluster.local(SVC NAME.NAMESPACE.svc.cluster.local)时,集群的 coreDNS 服务将返回一个值 my.database.example.com 的 CANEM 记录。访问这个服务的工作方式和其他的相同,唯一不同的事重定向发生在 DNS 层,而且不会进行代理和转发
8、Ingress
Ingress 的功能与 service 大致相似,不同的是 ingerss 提供了7层的代理,而 service 只提供了 4 层代理,如果希望实现 https 的访问则可以使用 Ingress
实现原理
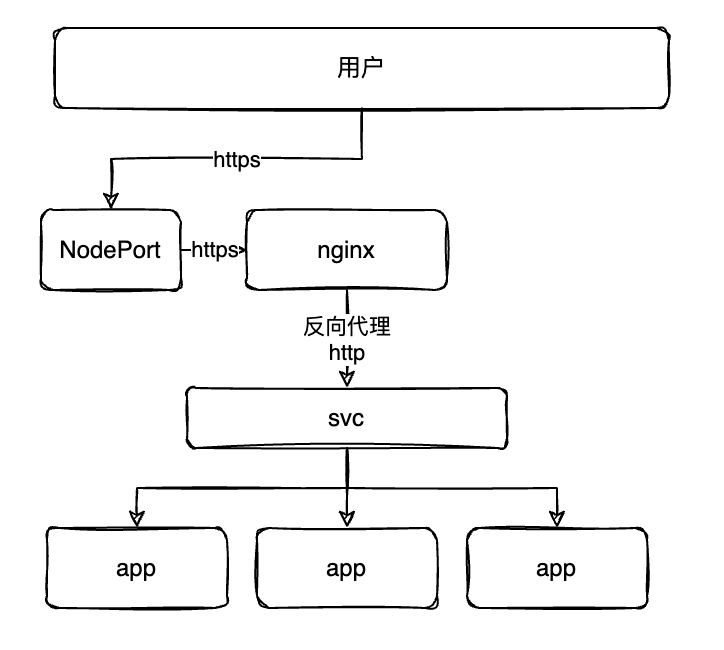
在 k8s 环境下创建一个 nginx pod,在内编写配置文件去反向代理 svc,同时提供 https 服务。其中的 nginx 在修改配置文件的状态下可能会造成服务的不稳定,所以 ingress 的 nginx 版本是不同的,具体逻辑见下图:
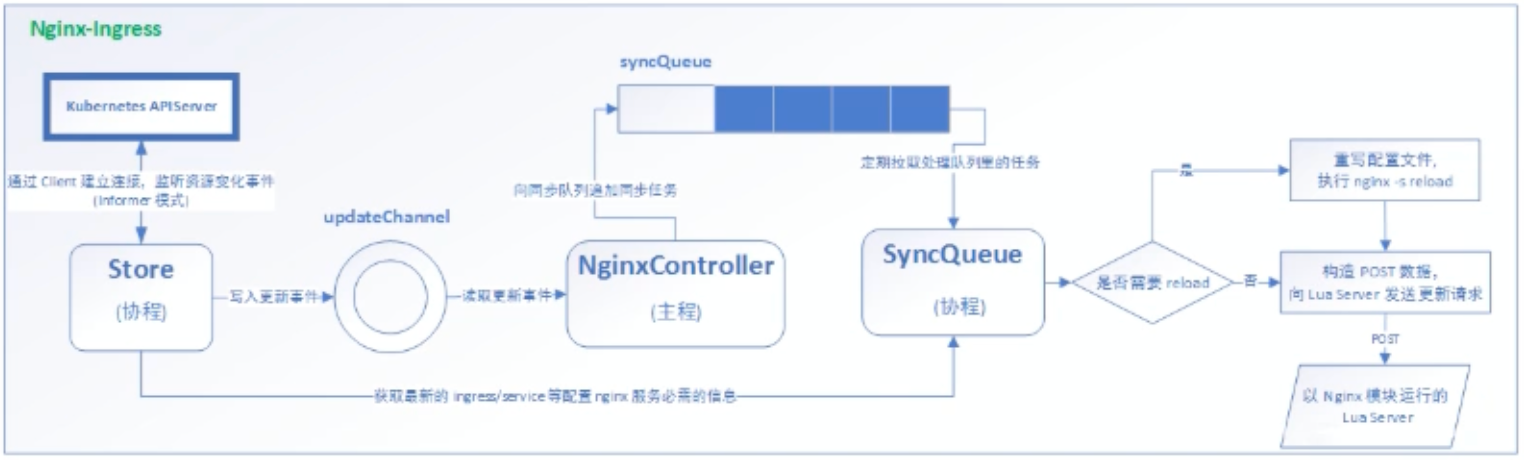
示例
http代理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: myapp
spec:
replicas: 2
template:
metadata:
labels:
name: app
spec:
containers:
- name: nginx
image: myapp:v1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: app-svc
spec:
ports:
- port: 80
targetPort: 80
protocol: TCP
selector:
name: app
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: app-ingress
spec:
rules:
- host: test.localhost
http:
paths:
- path: /
backend:
serviceName: app-svc
servicePort: 80
|
可以发现 Ingress 依赖与 svc,避免依赖动态的服务副本数量频繁重启 Ingress
https代理
创建 https 证书,以及创建 secret 对象进行存储
1
2
3
|
# 创建证书
openssl req -x509 -sha256 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/CN=nginxsvc /O=nginxsvc"
kubectl create secret tls tls-secret --key tls.key --cert tls.crt
|
配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: app-ingress
spec:
tls:
- hosts:
- test.localhost
secretName: tls-secret
rules:
- host: test.localhost
http:
paths:
- path: /
backend:
serviceName: app-svc
servicePort: 80
|
BasicAuth
创建密钥对
1
2
3
|
yum -y install httpd-tools
htpasswd -c auth foo
kubectl create secret generic basic-auth --form-file=auth
|
配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-with-auth
anntations:
nginx.ingress.kubernetes.io/auth-type: basic
nginx.ingress.kubernetes.io/auth-secret: basic-auth
nginx.ingress.kubernetes.io/auth-realm: 'Authentication Required - foo'
spec:
rules:
- host: test.localhost
http:
paths:
- path: /
backend:
serviceName: app-svc
servicePort: 80
|
Nginx 进行重写
| 名称 |
描述 |
值 |
| nginx.ingress.kubernetes.io/rewrite-target |
必须重定向流量的目标 URL |
字符串 |
| nginx.ingress.kubernetes.io/ssl-redirect |
指示位置部分是否仅可访问SSL(当 Ingress 包含证书时默认为 true) |
布尔 |
| nginx.ingress.kubernetes.io/force-ssl-redirect |
即使 Ingress 未启用 TLS,也强制重定向到 HTTPS |
布尔 |
| nginx.ingress.kubernetes.io/app-root |
定义 Controller 必须重定向到应用程序根,如果它在 ‘/’ 上下文中 |
字符串 |
| nginx.ingress.kubernetes.io/use-regex |
指示 Ingress 上定义当路径是否使用正则表达式 |
布尔 |
9、存储
K8S 集群中存储常用的有以下 4 种
- ConfigMap: 一般用于存储配置信息
- Secret: 存储一些安全类型的内容,例如存储密钥
- Volume: 卷,可以保障 Pod 级别的文件存储
- Persistent Volume: 持久卷
ConfigMap
描述
ConfigMap 功能在 Kubernetes 1.2 版本中引入,许多应用程序会从配置文件、命令行参数或环境变量中读取配置信息。ConfigMap 可以被用来保存单个属性,也可以用来保存整个配置文件或者 JSON 二进制等对象
创建
使用目录创建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
ls /root/game
# game.file
# ui.file
cat /root/game/game.file
# version=1.17
# name=dave
# age=18
cat /root/game/ui.file
# level=2
# color=yellow
kubectl create configmap game-config --from-file=/root/game
|
-from-file指定在目录下当所有文件都会被用在 ConfigMap 里面创建一个键值对,键的名称就是文件名,值就是文件的内容
使用文件创建
只要指定为一个文件就可以从单文件中创建 ConfigMap
1
|
kubectl create configmap game-config-2 --from-file=/root/game/game.file
|
--form-file这个参数可以使用多次、可以使用两次分别指定三个实例中的那两个配置文件,效果和指定整个目录是一样的
使用字面值创建
使用文字创建,利用-from-literal参数传递配置信息,该参数可以使用多次,格式如下
1
2
3
|
kubectl create configmap literal-config --from-literal=name=dave --from-literal=password=pass
kubectl get configmap literal-config -o yaml
|
使用
使用 ConfigMap 来代替环境变量
创建两个 ConfigMap
1
2
3
4
5
6
7
8
|
apiVersion: v1
kind: ConfigMap
metadata:
name: literal-config
namespace: default
data:
name: dave
password: pass
|
1
2
3
4
5
6
7
|
apiVersion: v1
kind: ConfigMap
metadata:
name: env-config
namespace: default
data:
log_level: INFO
|
在 Pod 中使用 ConfigMap
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
apiVersion: v1
kind: Pod
metadata:
name: cm-env-test-pod
spec:
containers:
- name: test-container
image: myapp:v1
command: ["/bin/sh", "-c", "env"]
env: # 单个指定
- name: USERNAME
valueFrom:
configMapKeyRef:
name: literal-config
key: name
- name: PASSWORD
valueForm:
configMapKeyRef:
name: literal-config
key: password
envFrom: # 批量注入
- configMapRef:
name: env-config
restartPolicy: Never
|
使用 ConfigMap 设置命令行参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
apiVersion: v1
kind: Pod
metadata:
name: cm-env-test-pod
spec:
containers:
- name: test-container
image: myapp:v1
command: ["/bin/sh", "-c", "echo $(USERNAME) $(PASSWORD)"]
env: # 单个指定
- name: USERNAME
valueFrom:
configMapKeyRef:
name: literal-config
key: name
- name: PASSWORD
valueForm:
configMapKeyRef:
name: literal-config
key: password
restartPolicy: Never
|
通过数据卷插件使用 ConfigMap
在数据卷里面使用这个 ConfigMap,有不同的选项、最基本的就是将文件填入数据卷,在这个文件中,键就是文件名称,值就是文件内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
apiVersion: v1
kind: Pod
metadata:
name: cm-volume-test-pod
spec:
containers:
- name: test-container
image: myapp:v1
volumeMounts:
- name: config-volume
mountPath: /etc/config
volumes:
- name: config-volume
configMap:
name: literal-config
restartPolicy: Never
|
热更新
在通过数据卷插件的形式使用 ConfigMap 时,可以达到热更新的目的,修改 ConfigMap 之后,在 Pod 中的对应文件内容也将修改成对应修改后的内容
创建初始 ConfigMap & Pod
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
# 初始内容
apiVersion: v1
kind: ConfigMap
metadata:
name: log-cofnig
namespace: default
data:
log_level: INFO
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: hot-update
spec:
replicas: 1
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: myapp:v1
ports:
- containerPort: 80
volumeMounts:
- name: config-volume
mountPath: /etc/config
volumes:
- name: config-volume
configMap:
name: log-config
|
查看内容
1
2
|
kubectl exec pod-xxx cat /etc/config/log_level
# INFO
|
修改 ConfigMap
1
2
|
kubectl edit cm log-config
# log_level=ERROR
|
再次查看内容,需要一定时间
1
2
|
kubectl exec pod-xxx cat /etc/config/log_level
# ERROR
|
**注意:**如果 configMap 以 ENV 的方式挂载,修改并不会实现热更新
滚动更新Pod
在更新 ConfigMap 之后并不会触发 Pod 的滚动更新,可以通过修改 Pod annotations 的方式来强制出发滚动更新
1
|
kubectl patch deploy my-nginx --patch '{"spec": {"template": {"metadata": {"anntations": {"version/config": "20190411"}}}}}'
|
这个例子里我们在.spec.template.metadata.annotations中添加version/config,每次通过修改version/config来触发滚动更新
Secret
解决了密码、token、密钥等敏感数据等配置问题,而不需要把这些敏感数据暴露到镜像或者 Pod Spec 中。Secret 可以以 Volume 或者环境变量方式使用
Secret有三种类型:
- Service Account:用来访问 Kubernetes API,由 Kubernetes 自动创建,并且会自动挂载到 Pod 的
/run/secrets/kubernetes.io/serviceaccount目录中
- Opaque:base64 编码格式的 Secret,用来存储密码、密钥等
- kubernetes.io/dockerconfigjson:用来存放私有 docker 仓库等认证信息
Service Account
用来访问 Kubernetes API,由 Kubernetes 自动创建,并且会自动挂载到 Pod 的 /run/secrets/kubernetes.io/serviceaccount目录中
1
2
3
4
|
kubectl exec pod-xxx -- ls /run/secrets/kubernetes.io/serviceaccount
# ca.crt
# namespace
# token
|
Opaque Secret
Opaque 类型的数据是一个 map 类型,要求 value 是 base64 编码格式
创建
1
2
3
4
|
$ echo -n "admin" | base64
YWRtaW4=
$ echo -n "123456" | base64
MTIzNDU2
|
secrets.yaml
1
2
3
4
5
6
7
8
|
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4=
password: MTIzNDU2
|
secret 在挂载后会自动解密
使用
1、将 Secret 挂载到 Volume 中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
apiVersion: v1
kind: Pod
metadata:
labels:
name: secret-test
name: secret-test
spec:
volumes:
- name: volumes12
secret:
secretName: mysecret
containers:
- image: myapp:v1
name: db
volumeMounts:
- name: volumes12
mountPath: "/data"
|
2、将 Secret 导出到环境变量中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
labels:
name: pod-deployment
spec:
replicas: 2
template:
metadata:
labels:
app: pod-deployment
spec:
containers:
- name: pod-1
image: myapp:v1
ports:
- containerPort: 80
env:
- name: TEST_USER
valueFrom:
secretKeyRef:
name: mysecret
key: username
- name: TEST_PASSWORD
valueFrom:
secretKeyRef:
name: mysecret
key: password
|
kubernetes.io/dockerconfigjson
使用 kubectl 创建 docker 仓库认证的 secret
1
2
3
4
5
6
7
|
$ kubectl create secret docker-registry myregistrykey \
--docker-server=DOCKER_REGISTRY_SERVER \
--docker-username=DOCKER_USER \
--docker-password=DOCKER_PASSWOED \
--docker-email=DOCKER_EMAIL
secret "myregistrykey" created。
|
在创建 Pod 的时候,通过 imagePullSecrets来引用刚创建的myregistrykey
1
2
3
4
5
6
7
8
9
10
|
apiVersion: v1
kind: Pod
metadata:
name: foo
spec:
containers:
- name: foo
image: hub.xxx.com/xxx/xxxx
imagePullSecrets:
- name: myregistrykey
|
Volume「卷」
容器磁盘上的文件等生命周期是短暂的,这就使得在容器中运行重要应用时会出现一些问题。首先,当容器崩溃时,kubelet 会重启它,但是容器中的文件将丢失,容器将以干净的状态(镜像最初的状态)重新启动。其次,在Pod中同时运行多个容器时,这些容器之间通常需要共享文件。Kubernetes 中的 Volume 抽象就很好的解决了这些问题。
Kubernetes 中的卷有明确的寿命(与封装它的 Pod 相同)。所以,卷的生命比 Pod 中的所有容器都长,当这个容器重启时数据仍然得以保存。当然,当 Pod 不再存在时,卷也将不复存在。也许更重要的是,Kubernetes 支持多种类型的卷,Pod 可以同时使用任意数量的卷
类型
kubernetes 支持以下类型的卷:
csi 通用存储接口hostPath 主机路径(不能限制使用量)emptyDir 空目录awsElasticBlockStore azureDisk azureFile cephfs downwardAPIfc flocker gcePersistentDisk gitRepo glusterfs hostPath iscsi local nfspersistentVolumeClaim projected portworxVolume quobyte rbd scaleIO secretstorageos vsphereVolume
emptyDir
当 Pod 被分配给节点时,首先创建 emptyDir 卷,并且只要该 Pod 在该节点上运行,该卷就会存在。正如卷名字所述,它最初时空的。Pod 中的容器可以读取喝写入 emptyDir 卷中的相同文件,尽管该卷可以挂载到每个容器中的相同或不同路径上。当出于任何原因从节点中删除 Pod 时,empryDir 中的数据将被永久删除
⚠️注意: 容器崩溃不会从节点中移除 Pod,因此 emptyDir 卷中的数据在容器崩溃时是安全的
用法:
- 暂存空间,例如用于基于磁盘的合并排序、用作长时间计算崩溃恢复时的检查点
- Web 服务器容器提供数据时,保存内容管理器提取的文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
apiVersion: batch/v1
kind: Job
metadata:
name: jobs-empty
spec:
template:
spce:
restartPolicy: Never
initContainers:
- name: job-1
image: busybox:1.34.1
command:
- "sh"
- "-c"
- >
for i in 1 2 3;
do
echo "job-1 `date`";
sleep 1s;
done;
echo job-1 GG > /src/input/code
volumeMounts: # 挂载一个卷
- name: input
mountPath: /src/input/
- name: job-2
image: busybox:1.34.1
command:
- "sh"
- "-c"
- >
for i in 1 2 3;
do
echo "job-2 `date`";
sleep 1s;
done;
cat /src/input/code &&
echo job-2 GG > /sec/input/output/file
volumeMounts: # 挂载两个卷
- name: input
mountPath: /src/input/
- name: output
mountPath: /src/input/output/
containers:
- name: job-3
image: busybox:1.34.1
command:
- "sh"
- "-c"
- >
echo "job-1 and job-2 completed";
sleep 3s;
cat /src/output/file
volumeMounts:
- name: output
mountPath: /src/output/
volumes:
- name: input
emptyDir: {}
- name: output
emptyDir: {}
|
hostPath
hostPath 卷将主机节点的文件系统中的文件或目录挂载到集群中
用途如下:
- 运行需要访问 Docker 内部的容器;使用
/var/lib/docker 的 hostPath
- 在容器中运行 cAdvisor; 使用
/dev/cgroups 的 hostPath
- 允许 Pod 指定给定的 hostPath 是否应该在 Pod 运行之前存在,是否应该创建,以及它应该以什么形式存在
除了所需的 path 属性之外,用户还可以为 hostPath 卷指定 type
| 值 |
行为 |
|
空字符串(默认)用于向后兼容,这意味着在挂载 hostPath 卷之前不会执行任何检查 |
DirectoryOrCreate |
如果在给定的路径没有任何东西存在,那么将根据需要在那里创建一个空目录,权限设置为 0755,与 kubelet 具有相同的组喝所有权 |
Directory |
给定的路径下必须存在目录 |
FileOrCreate |
如果在给定的路径没有任何东西存在,那么将根据需要在那里创建一个空文件,权限设置为 0655,与 kubelet 具有相同的组喝所有权 |
File |
给定的路径下必须存在文件 |
Socket |
给定的路径下必须存在 UNIX 套接字 |
CharDevice |
给定的路径下必须存在字符设备 |
BlockDevice |
给定的路径下必须存在块设备 |
使用这种卷类型时请注意,因为:
- 由于每个节点上的文件都不同,具有相同配置(例如从 PodTemplate 创建的)的 Pod 在不同节点上的行为会有所不同
- 当 Kubernetes 按照计划添加资源感知调度时,将无法考虑
hostPath 使用的资源
- 在底层主机上创建的文件或目录只能由 root 写入,您需要在特权容器中以 root 身份运行进程,或修改主机上的文件权限以便写入 hostPath 卷
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: myapp:v1
name: test-container
volumeMounts:
- name: test-volume
mountPath: /test-pd
volumes:
- name: test-volume
hostPath:
path: /data
type: Dirctory
|
Persistent Volume「持久卷」
概念
PersistentVolume(PV)
是由管理员设置的存储,它是集群的一部分,就像节点是集群中的资源一样,PV 也是集群中的资源。PV 是 Volume 之类的卷插件,但具有独立于使用 PV 的 Pod 的生命周期。此 API 对象包含存储实现的细节,即 NFS、ISCSI 或特定于云供应商的存储系统
PersistentVolumeClaim(PVC)
是用户存储的请求,它与 Pod 相似。Pod 消耗节点资源,PVC 消耗 PV 资源。Pod 可以请求特定级别的资源(CPU 和 内存)。声明可以请求特定的大小和访问模式(例如:可以以读/写一次或只读多次模式挂载)
静态PV
集群管理员创建一些 PV。它们带有可供集群用户使用的实际存储的细节。它们存在于 Kuberneters API 中,可用于消费。
动态PV
当管理员创建的静态 PV 都不匹配用户的 PVC 时,集群可能会尝试动态的为 PVC 创建卷。此配置基于 StorageClasses: PVC 必须请求 「存储类」,并且管理员必须创建并配置该类才能进行动态创建。声明该类为 "" 可以有效的禁用其动态配置
要启用基于存储级别的动态存储配置,集群管理员需要启用 API server 上的 DefaultStorageClass「准入控制器」。例如,通过确保 DefaultStorageClass 位于 API server 组件的 --admission-control 标志,使用逗号分隔的有序值列表中,可以完成此操作
绑定
master 中的控制环路监听新的 PVC,寻找匹配的 PV(如果可能),并将它们绑定在一起。如果为新的 PVC 动态掉配 PV,则该环路将始终将 PV 绑定到 PVC,否则用户总会得到他们所请求的存储,但是容量可能超出要求的数量。一旦 PV 和 PVC 绑定后,PersistentVolumeClaim 绑定是排他性的,不管它们是如何绑定的。PVC 跟 PV 绑定是一对一的映射
保护
PVC 保护的目的是确保由 Pod 正在使用的 PVC 不会从系统中移除,因为如果被移除的话可能会导致数据丢失
⚠️**注意:**当 Pod 状态为 Pending 并且 Pod 已经分配给节点或 Pod 为 Running 状态时,PVC处于活跃状态
当启用 PVC 保护 alpha 功能时,如果用户删除了一个 Pod 正在使用的 PVC,则该 PVC 不会被立即删除。PVC 的删除将被推迟,直到 PVC 不再被任何 Pod 使用
分类
PersistentVolume 类型以插件形式出现。Kubernetes 目前支持以下插件类型:
HostPathGCEPersistentDisk AWSElasticBlockStore AzureFile AzureDisk FC(Fibre Channel)FlexVolume Flocker NFS iSCSI RBD CephFS Cinder(OpenStack block storage)Glusterfs VsphereVolume Quobyte Volumes Vmware Photon Portworx VoumesScaleIO Volumes StorageOS
持久卷示例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0001
spec:
capacity: # 容量
storage: 5Gi
volumeMode: Filesystem # 卷模式
accessModes: # 访问策略
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle # 回收策略
storageClassName: slow # 存储类名称 默认为 StorageClass
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /tmp
server: 172.17.0.2
|
访问模式
PV 可以以资源提供者支持的任何形式挂载到主机上。如下表所示,供应商具有不同的功能,每个 PV 的访问模式都将被设置为该卷支持的特定模式。例如,NFS 可以支持多个读/写客户端,但特定的 NFS PV 可能以只读方式导出到服务器上。每个 PV 都有一套自己的用来描述特定功能的访问模式
- ReadWriteOnce 该卷可以被单个节点以读/写模式挂载
- ReadOnlyMany 该卷可以被多个节点以只读模式挂载
- ReadWriteMany 该卷可以被多个节点以读/写模式挂载
在命令行中,访问模式缩写为:
- RWO - ReadWriteOnce
- ROX - ReadOnlyMany
- ReadWriteMany - RWX
⚠️**注意:**一个卷一次只能使用一种访问模式挂载,即使它支持很多访问模式。例如,GCRPersistentDisk 可以由单个节点作为 ReadWriteOnce 模式挂载,或由多个节点以 ReadOnlyMany 模式挂载,但不能同时挂载
回收策略
- Retain(保留):手动回收
- Recycle(回收):基本擦除(
rm -rf /thevolume/*)
- Delete(删除):关联的存储资产(例如 AWS EBS…)将被删除
当前,只有 HostPath 支持回收策略,AWS EBS、GCE PD、Azure Disk 和 Cinder 卷支持删除策略
状态
卷可以处于一下的某种状态:
- Available(可用):一块空闲资源还没有被任何声明绑定
- Bound(已绑定):卷已经被声明绑定
- Released(已释放):声明被删除,但是资源还未被集群重新声明
- Failed(失败):该卷的自动回收失败
命令行会显示绑定到 PV 的 PVC 的名称
 RoninZc 收录于 学习
RoninZc 收录于 学习