一、前言
最近在考虑PAAS移动平台的”动态字段存储”问题,简单来说就是前段某页面中的表单动态增加一个编辑框,以某一个新字段的形式提交到后端,后端接口能够在不增加新的表字段且基本不需要修改代码的方式存储起来。
我们都知道,关系型数据库MySQL的数据表在修改表字段时,代价比较大,甚至出现锁表导致服务奔溃。有什么好的办法呢?下面我仍然基于MySQL,对比了两种可行的方法,希望对你有帮助。
二、动态结构
关系数据库非常适合具有大量关系的结构化数据,它所存储的数据都是预先能够定义出清晰的结构,并且短期或更长的时间内结构不会发生变化。但是业务总是不断在变化的,业务在扩展,存储的信息必然更多更广,表结构发生变化几乎是不可避免。
为了解决”动态结构”的问题也有不少轻易能够想到的方法:
- 列模型:就是常说的”宽表”,为了应对表结构的改变,我们可以在设计表结构的时候,预留多一些空白字段,简单好理解,但是容易造成数据的”稀疏性”,同时长远看来宽表太宽存储性能很差,太窄会满足不了业务变化。
- 行模型:就是以key-value结构作为一行存储到表中,每增加一个字段就新增一行数据,兼顾灵活性,问题在于value定义类型只能是varchar,大小也需要做限制。
- NoSQL:利用NoSQL基于document类型的特性,可以很方便地存储动态结构并且查询效率高,但问题在于业务改造成本大,同时需要ACID事务的场景支持度不够。
还有一种模型,目前在诸如医疗数据库、犯罪数据库和大型电商类数据等有着广泛应用的成熟模型:EAV模型,也即是以”实体-属性-值”来组织数据。
EAV模型
在开源和php社区,最著名的EAV实现是Magento,一个电子商务平台。EAV模型,就是把实体-属性-值(Entity-Attribute-Value)分开表进行存储。实体表存储对象的ID和主要属性,属性表存储需要扩展的属性,值表由不同类型的表组成一个集合,一个值需要由实体ID+属性ID来确定。
为了方便查找某一个实体具备哪些属性,可以增加实体类型(type_id),基于实体的类型,可以通过查找eav_attribute来找到要设置产品的那一属性。当需要操作某一个实体的属性时,就可以先把实体拥有的属性先查出来,再对属性进行操作,设置属性值时,先判断属性的类型是什么,再找到对应类型的值表,然后更新改属性的值。
虽然EAV模型能够解决以上三种模型的缺点,有着灵活性强,完美解决数据稀疏性,但是它也因为太过于复杂,有着明显的学习曲线,查询性能也相对低下,必须为其提升性能做大量的辅助工作。
我的目标是寻找一种动态结构的数据的模型性能可与文档数据库相媲美,结构更简单比EAV更具可读性。那就是MySQL5.7以后支持的JSON类型,也就表字段类型为JSON,用于存储动态扩展字段。
JSON模型
JSON模型,比较MySQL5.7以前使用text类型来存文本JSON的方式,JSON模型兼顾了性能及易用性,在操作和性能上都得到很大的提升。JSON类型是以二进制方式存储的,要比字符串更加高效,再也不用json序列化近文本字段,查询之后还要解析,同时还要兼顾json的合法性。
在MySQL 5.7.8中,MySQL支持由RFC 7159定义的本地JSON数据类型,它支持对JSON(JavaScript对象标记)文档中的数据进行有效访问. 有如下几个特性:
- MySQL会对DML JSON数据自动验证。无效的DML JSON数据操作会产生错误.
- 优化的存储格式。存储在JSON列中的JSON文档转换为一种内部格式,允许对Json元素进行快速读取访问.
- MySQL Json类型支持建立索引增加查询性能提升.
另外有还有一种我认为收益比较大的是:虚拟列 Virtual Column
在MySQL 5.7中,支持两种Generated Column,即Virtual Generated Column和Stored Generated Column,前者只将Generated Column保存在数据字典中(表的元数据),并不会将这一列数据持久化到磁盘上;后者会将Generated Column持久化到磁盘上,而不是每次读取的时候计算所得。很明显,后者存放了可以通过已有数据计算而得的数据,需要更多的磁盘空间,与Virtual Column相比并没有优势,因此,MySQL 5.7中,不指定Generated Column的类型,默认是Virtual Column。
有了虚拟列,在select子句和where子句中,查询虚拟列与普通的列没有不同,查询用法上可以基本不需要变化。同时由于虚拟列的特性,只是与json中的属性key的一种映射关系,所以虚拟列的增删性能是非常好的。
另外,在建立了虚拟列之后,可以继续对虚拟列建立索引,可以提升查询性能,有了索引,性能几乎跟普通没有区别。
下面的第五节的模型操作对比中会给出一些JSON操作的实例,更多参考官方文档:https://dev.mysql.com/doc/refman/5.7/en/json.html
下面给出列模型、行模型、EAV模型和JSON模型的优缺点及表结构对比:
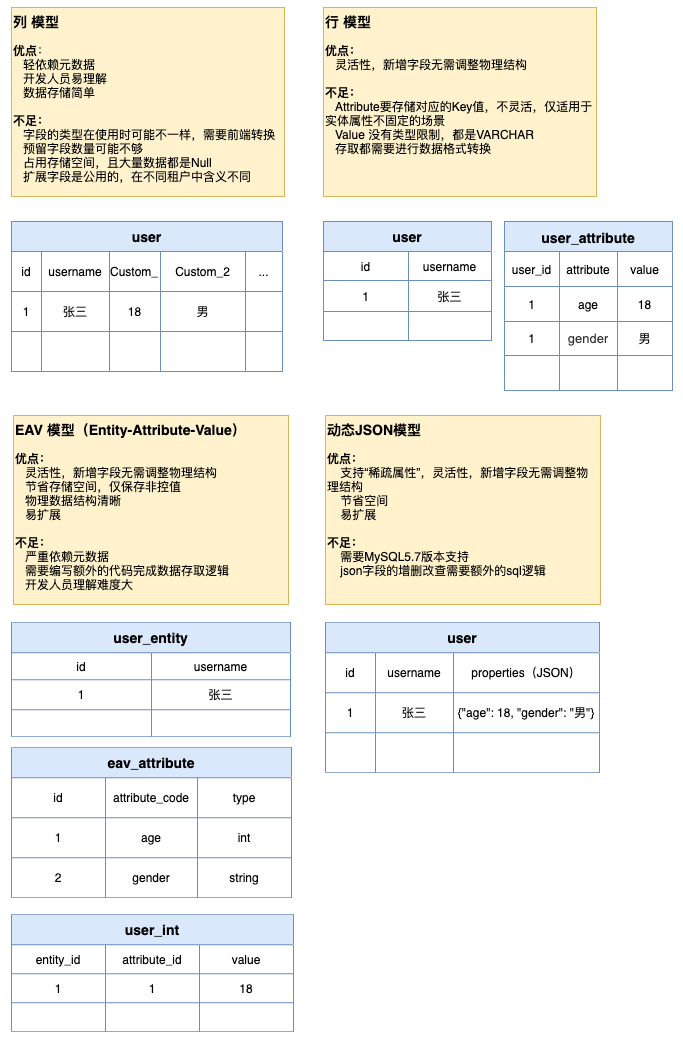
由于列模型、行模型和NoSQL都是比较容易理解和常见,所以下文重点只对EAV模型和JSON模型进行分析和对比
三、性能测试结果对比
下面是两种模型参与性能测试的SQL,包括查询,更新和插入数据,可以对比观察一下不同模型SQL的复杂度:
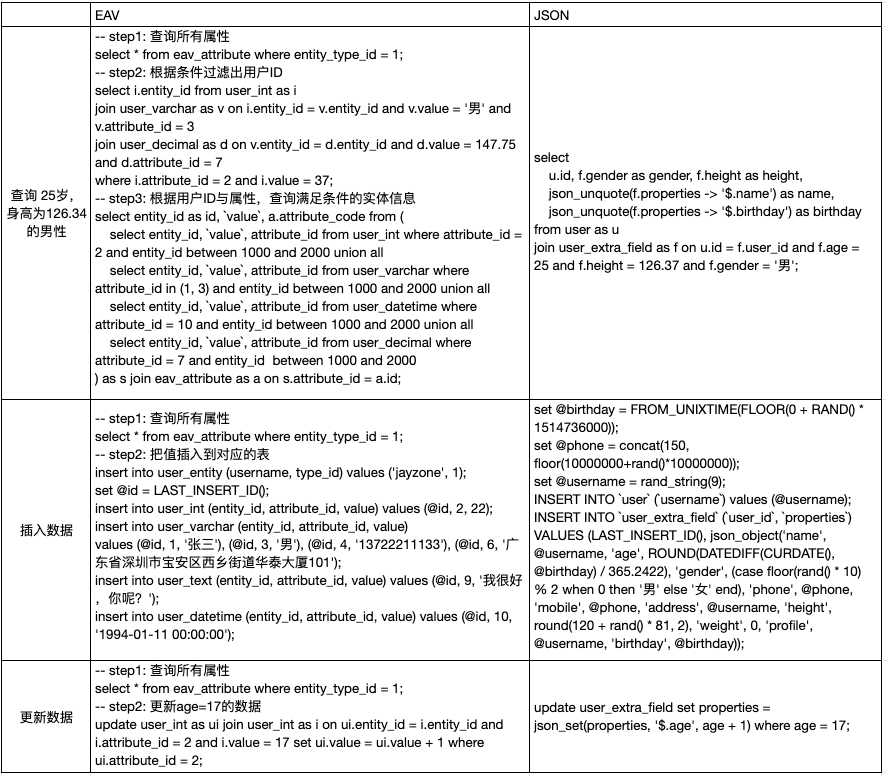
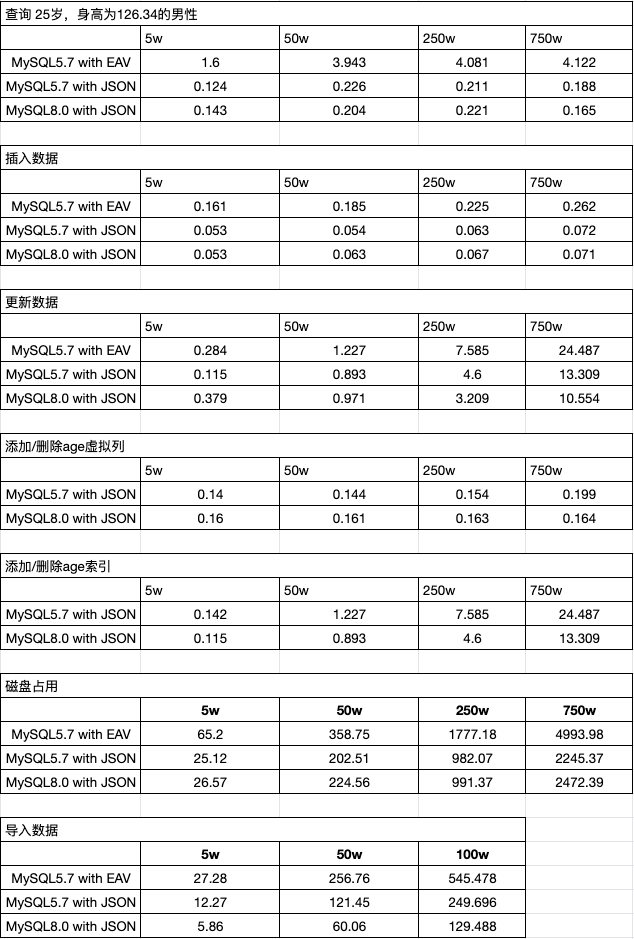
下面为SQL在不同量级的数据量时,从查询、更新、插入、建立字段和索引等操作维度,对比了EAV模型、MySQL5.7的JSON模型 和 MySQL8.0的JSON模型 的性能,另外对比了磁盘空间占用和数据导入性能
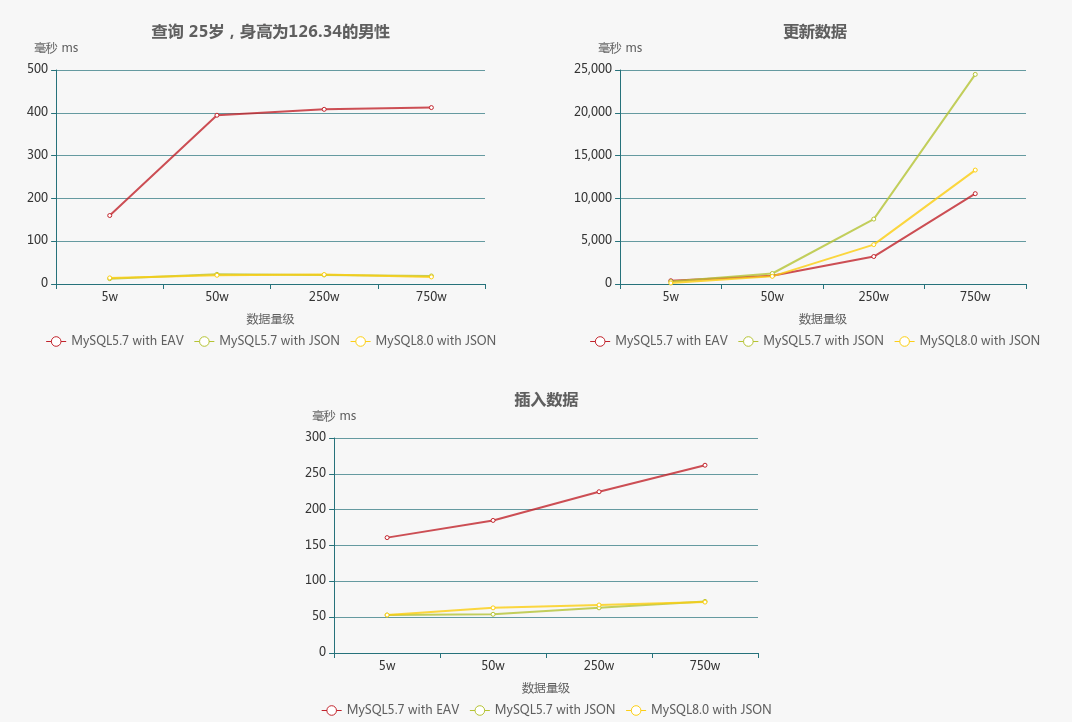
图表展示,方便查看趋势
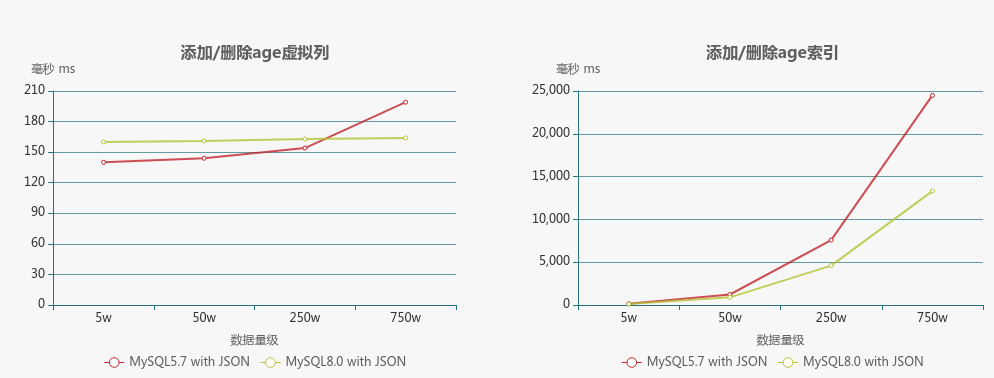
结论:
- 两种模型从操作的复杂度比较,EAV模型要复杂得多,查询不宜联查这么多的表,所以每次都必须分步骤,查询有哪些属性并拿到属性ID(当然可以利用缓存来优化),JSON模型只要有虚拟列,查询时与普通的方式没有却别,插入或更新时需要利用函数;
- 从查询性能来看,JSON模型明显优于EAV模型。不过虽然这样,EAV只要做好适当的缓存优化,其实是可以满足一定的场景并被接受;
- 无论在那个数量级下,JSON模型操作虚拟列时的消耗都是极快,而对于给虚拟列添加索引,性能会随着数据量级的增大而增加,毕竟需要建立索引树,也是正常操作了,与普通列的索引差不多;
- MySQL8.0对JSON类型也做了增强,对比MySQL5.7,在添加/删除索引的性能上,性能提升了接近一倍,虚拟列的操作性能在不同数据量级下,更加稳定;
由于测试用例还是比较粗略,所以不一定100%精准,发现哪里有问题,欢迎指正。
对EAV模型和JSON模型的表结构和增删改查等操作感兴趣的,请看第五节”动态存储模型实际案例”
四、总结
本篇为你介绍了动态结构的场景,并且列举了几个可行的存储模型:列模型(宽表),行模型,EAV模型和JSON模型,并且分析了各种模型的优缺点,通过实际的案例来对比分析了EAV模型和JSON模型,了解了这两种模型的实际操作的SQL语句,展示了不同的数据量级下的查询、插入和更新性能。
经过一番对比,相信你已经面对”动态结构”的场景时候,已经有据可依了,希望对你有帮助。
肝文章不易,点个赞再走。感谢!!
五、附加:动态存储模型实际案例
1. EAV模型(Entity-Attribute-Value Model)
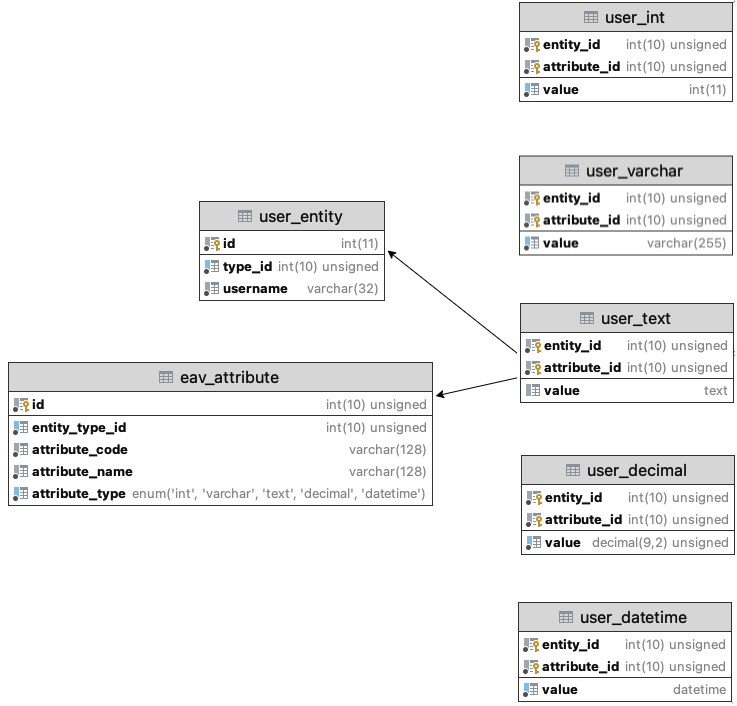
表结构
属性表
1
2
3
4
5
6
7
8
9
10
11
|
create table `eav_attribute`
(
`id` int unsigned not null auto_increment comment '属性ID',
`entity_type_id` int unsigned not null default 0 comment '实体类型ID',
`attribute_code` varchar(128) not null default '' comment '属性Code',
`attribute_name` varchar(128) not null default '' comment '属性名称',
`attribute_type` enum ('int', 'varchar', 'text', 'decimal', 'datetime') not null comment '属性类型',
primary key (`id`),
index `IDX_ENTITY_TYPE_ID` (`entity_type_id`),
index `IDX_TYPE` (`attribute_type`)
) engine = innodb charset = utf8mb4 comment 'eav属性表';
|
用户实体表
1
2
3
4
5
6
|
create table `user_entity`
(
id int auto_increment primary key comment '用户实体ID',
type_id int unsigned not null default 0 comment '实体类型ID',
username varchar(32) default '' not null comment '用户名'
) engine = innodb charset = utf8mb4 comment '用户实体表';
|
用户整型值表
1
2
3
4
5
6
7
8
|
create table `user_int`
(
`entity_id` int unsigned not null comment '实体ID',
`attribute_id` int unsigned not null comment '属性ID',
`value` int not null default 0 comment '整型值',
primary key (`entity_id`, `attribute_id`),
index `IDX_VALUE` (`value`)
) engine = innodb charset = utf8mb4 comment 'user整型值表';
|
用户字符串值表
1
2
3
4
5
6
7
8
|
create table `user_varchar`
(
`entity_id` int unsigned not null comment '实体ID',
`attribute_id` int unsigned not null comment '属性ID',
`value` varchar(255) not null default '' comment '字符值',
primary key (`entity_id`, `attribute_id`),
index `IDX_VALUE` (`value`)
) engine = innodb charset = utf8mb4 comment 'user字符值表';
|
用户文本值表
1
2
3
4
5
6
7
|
create table `user_text`
(
`entity_id` int unsigned not null comment '实体ID',
`attribute_id` int unsigned not null comment '属性ID',
`value` text comment '文本值',
primary key (`entity_id`, `attribute_id`)
) engine = innodb charset = utf8mb4 comment 'user文本值表';
|
用户浮点型值表
1
2
3
4
5
6
7
8
|
create table `user_decimal`
(
`entity_id` int unsigned not null comment '实体ID',
`attribute_id` int unsigned not null comment '属性ID',
`value` decimal(9, 2) unsigned not null comment '浮点值',
primary key (`entity_id`, `attribute_id`),
index `IDX_VALUE` (`value`)
) engine = innodb charset = utf8mb4 comment 'user浮点值表';
|
用户日期型值表
1
2
3
4
5
6
7
8
|
create table `user_datetime`
(
`entity_id` int unsigned not null comment '实体ID',
`attribute_id` int unsigned not null comment '属性ID',
`value` datetime not null comment '日期值',
primary key (`entity_id`, `attribute_id`),
index `IDX_VALUE` (`value`)
) engine = innodb charset = utf8mb4 comment 'user日期值表';
|
插入属性数据
1
2
3
4
5
6
7
8
9
10
11
|
INSERT INTO `eav_attribute` (id, entity_type_id, attribute_code, attribute_name, attribute_type)
VALUES (1, 1, 'name', '姓名', 'varchar'),
(2, 1, 'age', '年龄', 'int'),
(3, 1, 'gender', '性别', 'varchar'),
(4, 1, 'phone', '电话', 'varchar'),
(5, 1, 'mobile', '移动电话', 'varchar'),
(6, 1, 'address', '家庭住址', 'varchar'),
(7, 1, 'height', '身高(cm)', 'decimal'),
(8, 1, 'weight', '体重(kg)', 'decimal'),
(9, 1, 'profile', '简介', 'text'),
(10, 1, 'birthday', '出生年月', 'datetime');
|
2. JSON模型
表结构
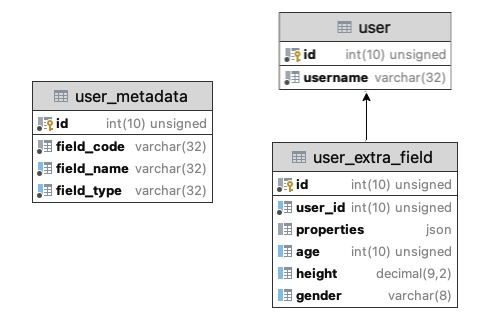
用户表
1
2
3
4
5
|
create table `user` (
`id` int unsigned not null auto_increment comment '用户ID',
`username` varchar(32) not null default '' comment '账号',
primary key(`id`)
) engine = innodb charset = utf8mb4 comment '用户主表';
|
用户源数据表
1
2
3
4
5
6
7
8
|
create table `user_metadata` (
`id` int unsigned not null auto_increment comment '用户元数据',
`field_code` varchar(32) not null default '' comment '字段code',
`field_name` varchar(32) not null default '' comment '字段名',
`field_type` varchar(32) not null default '' comment '字段类型',
primary key(`id`),
index `IDX_FIELD` (`field_name`, `field_type`)
) engine = innodb charset = utf8mb4 comment '用户元数据表';
|
用户扩展字段表
1
2
3
4
5
6
7
|
create table `user_extra_field` (
`id` int unsigned not null auto_increment comment '字段id',
`user_id` int unsigned not null default 0 comment '用户ID',
`properties` json default null comment '扩展字段',
primary key(`id`),
index `IDX_USER_ID` (`user_id`)
) engine = innodb charset = utf8mb4 comment '用户扩展字段表';
|
元数据
1
2
3
4
5
6
7
8
9
10
11
|
insert into `user_metadata` (id, field_code, field_name, field_type)
VALUES (1, 'name', '姓名', 'varchar'),
(2, 'age', '年龄', 'int'),
(3, 'gender', '性别', 'varchar'),
(4, 'phone', '电话', 'varchar'),
(5, 'mobile', '移动电话', 'varchar'),
(6, 'address', '家庭住址', 'varchar'),
(7, 'height', '身高(cm)', 'decimal'),
(8, 'weight', '体重(kg)', 'decimal'),
(9, 'profile', '简介', 'text'),
(10,'birthday', '出生年月', 'datetime');
|
说明:由于json类型里的数据类型也是只有字符串、数字、对象(JSON 对象)、数组、布尔和Null,所以使用元数据表把属性的具体类型存储起来,可以在必要时可以在代码层做类型转换逻辑。
模型操作对比
1. 字段操作
增加一个”edu”学历字段
EAV模型
只需要在属性表eav_attribute中增加一行即可
1
|
insert into eav_attribute (entity_type_id, attribute_code, attribute_name, attribute_type) values (1, 'edu', '学历', 'varchar');
|
JSON
需要在元数据表user_metadata增加一行,并且增加虚拟列edu以及其索引
1
2
|
alter table user_extra_field add column `edu` varchar(32) GENERATED ALWAYS AS (json_extract(`properties`,'$.edu')) VIRTUAL;
alter table user_extra_field add index `IDX_EDU` (`edu`);
|
删除mobile字段
EAV模型
需要三步:
- 查询mobile属性
- 删除属性记录
- 删除属性值
1
2
3
4
5
6
|
-- step1: 查询属性信息
select * from eav_attribute where entity_type_id = 1;
-- step2: 删除字段
delete from eav_attribute where id = 5;
-- step3: 删除值
delete from user_varchar where attribute_id = 5;
|
JSON模型
利用json_remove()方法,可以直接删除json字段对应的属性
1
2
3
4
5
6
|
-- step1: 删除字段
delete from user_metadata where field_code = 'mobile';
-- step2: 删除值
update user_extra_field set properties = json_remove(properties, '$.mobile');
-- step3: 删除虚拟列
alter table user_extra_field drop column `mobile`;
|
注意,第2、3步可以根据业务自身考虑是否有必要,为了节省空间,那些确定不再使用的属性字段可以考虑删除,缩小json体积。
2. 查询操作
查询身高高于170cm,年满18岁的男性用户
EAV模型
需要分三步进行查询,每一步的结果传递需要代码逻辑层实现,此处直接贴出所有的查询SQL
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
-- step1: 查询所有属性
select * from eav_attribute where entity_type_id = 1;
-- step2: 根据条件过滤出用户ID
select i.entity_id
from user_int as i
join user_varchar as v on i.entity_id = v.entity_id and v.value = '男' and v.attribute_id = 3
join user_decimal as d on v.entity_id = d.entity_id and d.value > 170 and d.attribute_id = 7
where i.attribute_id = 2 and i.value > 18;
-- step3: 根据用户ID与属性,查询满足条件的实体信息
select entity_id as id, `value`, a.attribute_code from (
select entity_id, `value`, attribute_id from user_int where attribute_id = 2 and entity_id in (1,3,4,6,10,13,17,18) union all
select entity_id, `value`, attribute_id from user_varchar where attribute_id in (1, 3) and entity_id in (1,3,4,6,10,13,17,18) union all
select entity_id, `value`, attribute_id from user_datetime where attribute_id = 10 and entity_id in (1,3,4,6,10,13,17,18) union all
select entity_id, `value`, attribute_id from user_decimal where attribute_id = 7 and entity_id in (1,3,4,6,10,13,17,18)
) as s join eav_attribute as a on s.attribute_id = a.id;
|
注意:查出来的结果,还需要进行key-value的转换
JSON模型
1
2
3
4
5
6
7
8
9
10
11
12
|
select
u.id,
json_unquote(f.properties -> '$.name') as name,
json_unquote(f.properties -> '$.gender') as gender,
f.properties -> '$.height' as height,
json_unquote(f.properties -> '$.birthday') as birthday
from user as u
join user_extra_field as f
on u.id = f.user_id
and f.properties -> '$.age' > 18
and f.properties -> '$.height' > 170
and f.properties -> '$.gender' = '男'
|
在建立了虚拟列的前提下,查询与传统的方式没有区别
1
2
3
|
select u.id,f.name,f.gender,f.height, f.birthday
from user as u
join user_extra_field as f on u.id = f.user_id and f.age > 18 and f.height > 170 and f.gender = '男'
|
查询用户详情:查询用户ID为3的用户信息
EAV模型 需要分两步:1. 查询所有的属性,2.根据属性ID和用户ID,查询属性值
1
2
3
4
5
6
7
8
9
10
11
|
-- step1: 查询所有属性
select * from eav_attribute where entity_type_id = 1;
-- step2: 根据属性及id,查询id为3的用户信息
select entity_id as id, `value`, a.attribute_code from (
select entity_id, `value`, attribute_id from user_int where attribute_id = 2 and entity_id = 3 union all
select entity_id, `value`, attribute_id from user_varchar where attribute_id in (1,3,4,5,6) and entity_id = 3 union all
select entity_id, `value`, attribute_id from user_decimal where attribute_id in (7, 8) and entity_id = 3 union all
select entity_id, `value`, attribute_id from user_text where attribute_id = 9 and entity_id = 3 union all
select entity_id, `value`, attribute_id from user_datetime where attribute_id = 10 and entity_id = 3
) as s join eav_attribute as a on s.attribute_id = a.id
|
JSON模型
1
|
select u.id, u.username, f.properties from user as u join user_extra_field as f on u.id = f.user_id where u.id = 3;
|
3. 插入数据
新增一条数据
1
2
|
insert into user (id, username, name, age, gender, phone, address, profile, birthday)
values (20, 'jayzone', '张三', 22, '男', '13722211133', '广东省深圳市宝安区西乡街道华泰大厦101', '我很好,你呢?', '1994-01-11');
|
EAV模型 分两步操作: 1.查询所有属性,2.根据属性ID和值,插入到对应的表中
1
2
3
4
5
6
7
8
9
10
|
-- step1: 查询所有属性
select * from eav_attribute where entity_type_id = 1;
-- step2: 把值插入到对应的表
insert into user_entity (id, username, type_id) values (20, 'jayzone', 1);
insert into user_int (entity_id, attribute_id, value) values (20, 2, 22);
insert into user_varchar (entity_id, attribute_id, value)
values (20, 1, '张三'), (20, 3, '男'), (20, 4, '13722211133'), (20, 6, '广东省深圳市宝安区西乡街道华泰大厦101');
insert into user_text (entity_id, attribute_id, value) values (20, 9, '我很好,你呢?');
insert into user_datetime (entity_id, attribute_id, value) values (20, 10, '1994-01-11 00:00:00');
|
JSON模型 需要使用**json_object()**方法构建json对象,在存入JSON字段中
1
2
3
|
insert into user (id, username) values (20, 'jayzone');
insert into user_extra_field (user_id, properties)
values (20, json_object('name', '张三', 'age', 22, 'gender', '男', 'phone', '13722211133', 'address', '广东省深圳市宝安区西乡街道华泰大厦101', 'profile', '我很好,你呢?', 'birthday', '1994-01-11'));
|
4. 更新数据
新增一个字段, 并且更新用户ID=3的用户学历为本科
EAV模型 需要在eav_attribute表中增加一行记录,然后更新对应的值
1
2
3
4
|
-- step1: 查询属性
select * from eav_attribute where entity_type_id = 1;
-- step2: 更新对应属性的值
update user_varchar set value = '本科' where entity_id = 3 and attribute_id = 11;
|
JSON模型 利用json_insert/json_set方法更新对应字段的值
1
|
update user_extra_field set properties = json_set(properties, '$.phone', '15016716555') where id = 3;
|
 RoninZc 收录于 学习
RoninZc 收录于 学习